利用Python爬取丁香园疫情数据
本文最后更新于:2020年4月13日 下午
疫情到现在过去很久了,国内已经大体控制下来了。这次的目标是爬取利用python爬取疫情数据(基于丁香园的数据)
这期本来3.9就创建了的,但一直拖到今天4.13才完成,还是太懒😂😂
准备:
- python及常用模块
- VS Code
- 浏览器
目标网址:https://ncov.dxy.cn/ncovh5/view/pneumonia?scene=2&clicktime=1579579384&enterid=1579579384&from=timeline&isappinstalled=0开始
1.抓包
首先是抓包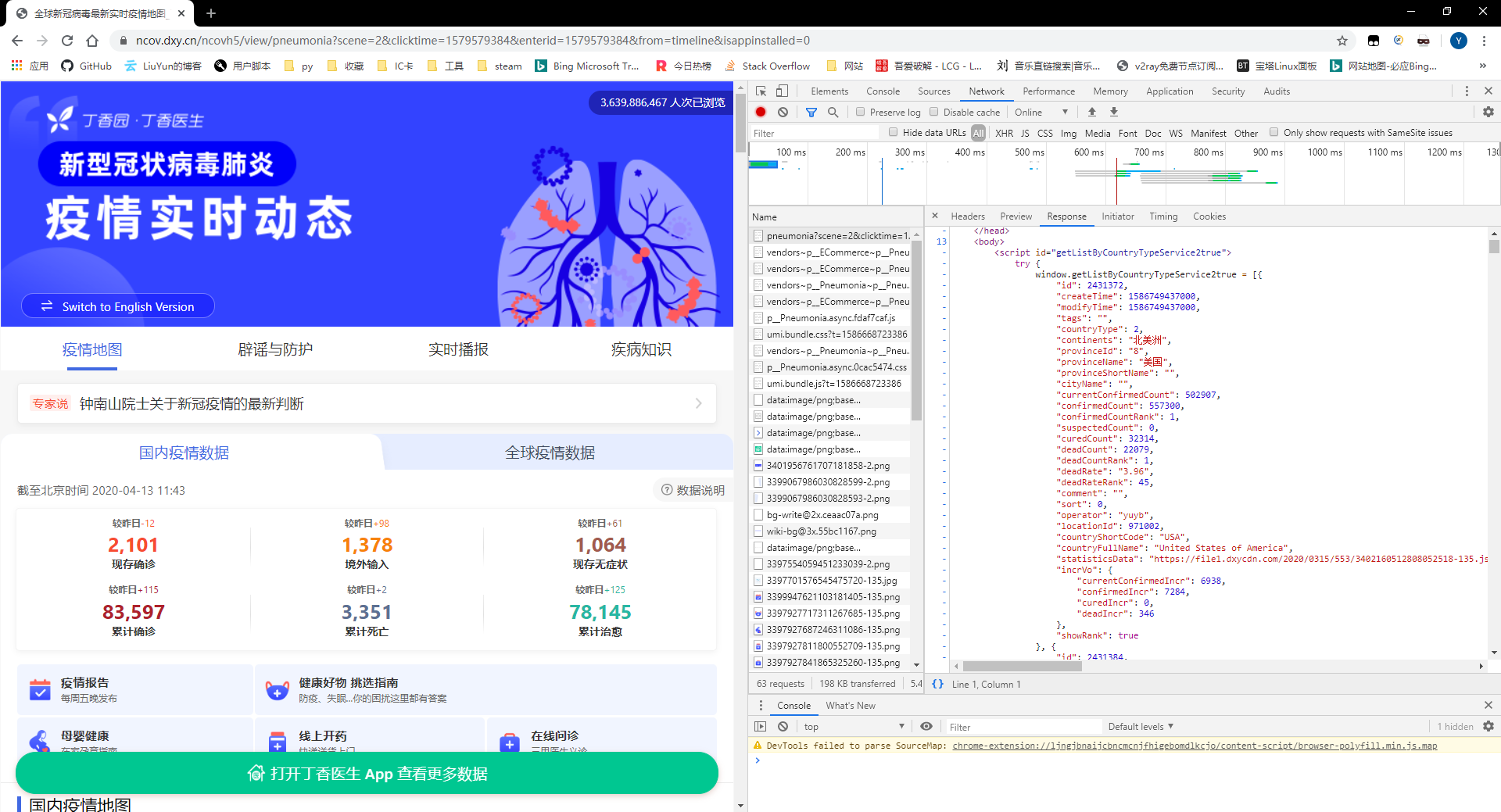
经过分析可以看出,该网页的数据不同于平常的一个框架+单独的json数据包,它是直接渲染好了给我们传过来的,所以要做的事情就比较简单了,只需要从html代码中提取出我们需要的数据。2.python代码编写
我们先实现获取html代码的代码,然后再尝试从中提取数据。这里指定了一下编码,是为了防止出现不必要的转码错误。1
2
3response = requests.get("https://ncov.dxy.cn/ncovh5/view/pneumonia?scene=2&clicktime=1579579384&enterid=1579579384&from=timeline&isappinstalled=0")
response.encoding = "utf-8"
body = response.text3.提取HTML中的代码
获取网页数据实现了,接下来我们分析一下数据的位置,以及该如何提取出来。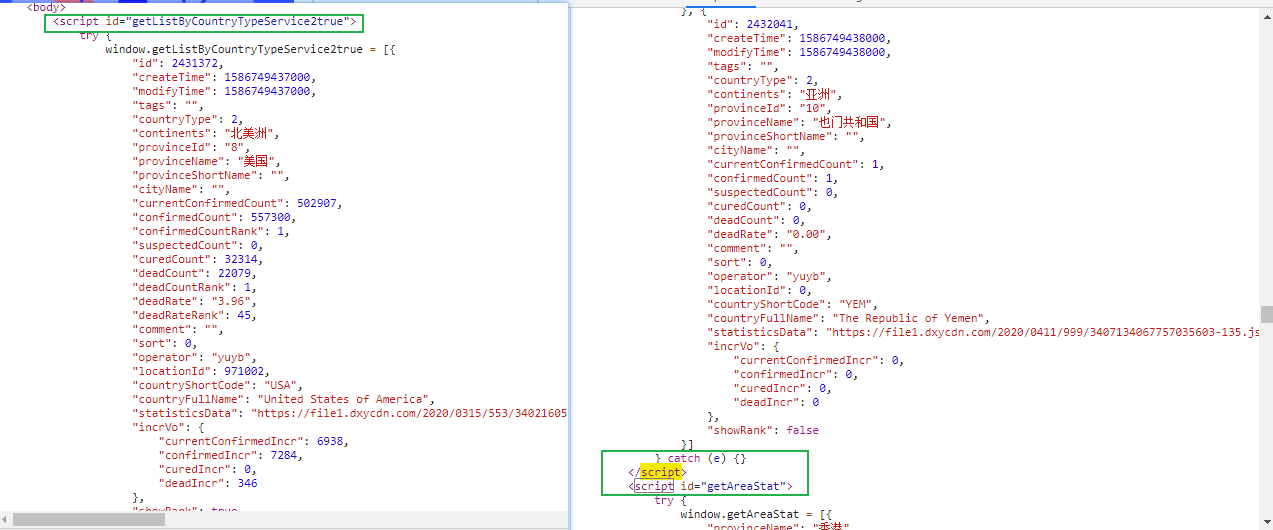
通过观察我们可以发现,它是利用一个script一个区域数据,分别对应的是全球地区,全国地区等,里面是一串类似是js代码,先不管,先把我们这次要的国内数据提代码取出来。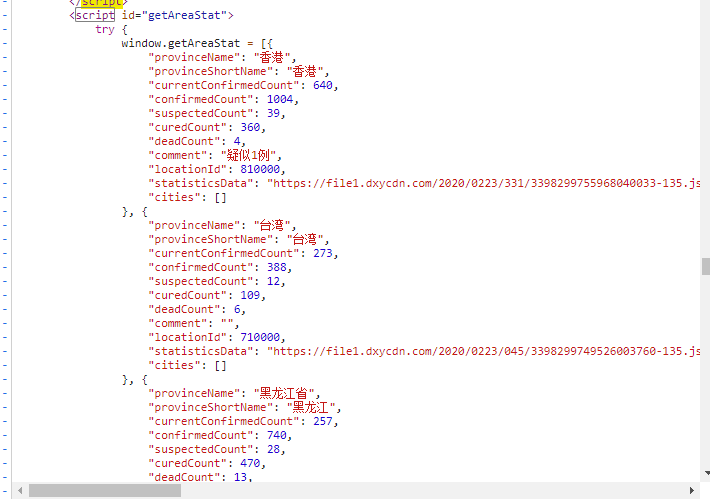
通过分析,国内的数据script对应的id值是“getAreaStat” 。因为是属于一个类里的,所以这里我用了xpath,代码如下:1
2html = etree.HTML(body, etree.HTMLParser())
gethtml = html.xpath('//*[@id="getAreaStat"]/text()')4.提取代码中的数据
经过上面的步骤,我们已经实现了提取出了国内数据的js代码,但是很明显我们只需要数据,而我们利用python也不可能执行这串window.getAreaStat代码,所以我们尝试删去赋值等代码,直接提取数据,因为里面的数据刚好符合json格式。
要删除的头数据
要删除的尾数据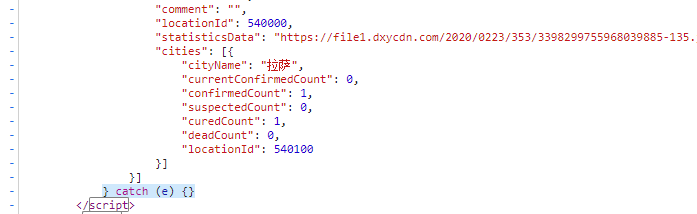
即这里[0]是因为前面xpath查找的返回的是list,因为我们指定了id,所以应该只能找到一个,并且正好是我们想要的,然后用[28:-12]提取出完美的json格式的数据。1
gethtml[0][28:-12]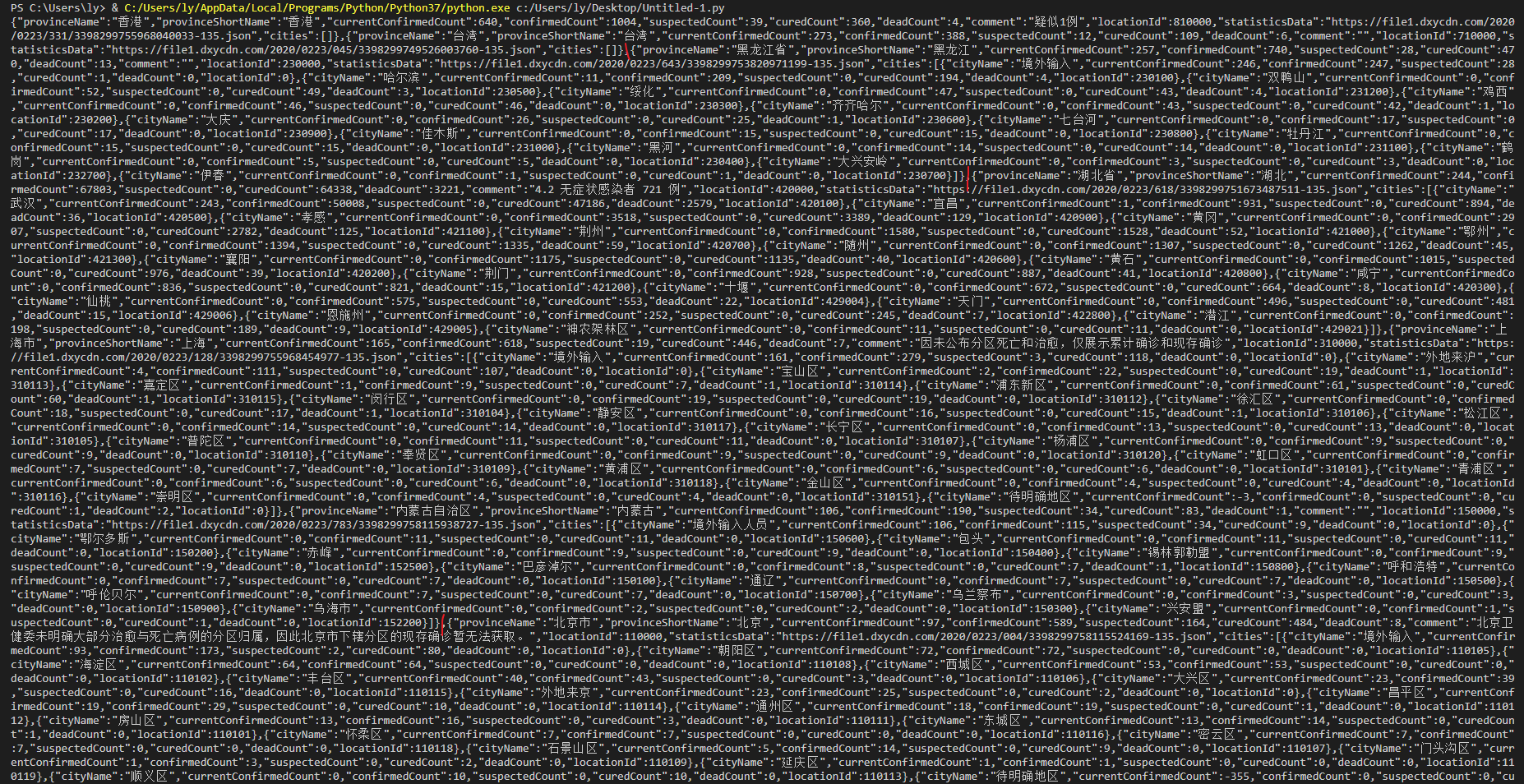
5.查找数据
虽然每个省份都是一个很好的json数据,但是我们要取的是整个省份,所以我们将其转化为列表,然后利用迭代,查找到我们需要的城市。然后我们调试看看1
2
3
4
5
6
7
8
9
10data=eval(gethtml[0][28:-12])
p_count="0"
c_count="0"
for i in data:
if str(i.get("provinceName")) == province:
p_count=str(i.get("confirmedCount"))
for c in i["cities"]:
if str(c.get("cityName")) == city[0:-1]:
c_count=c.get("confirmedCount")
break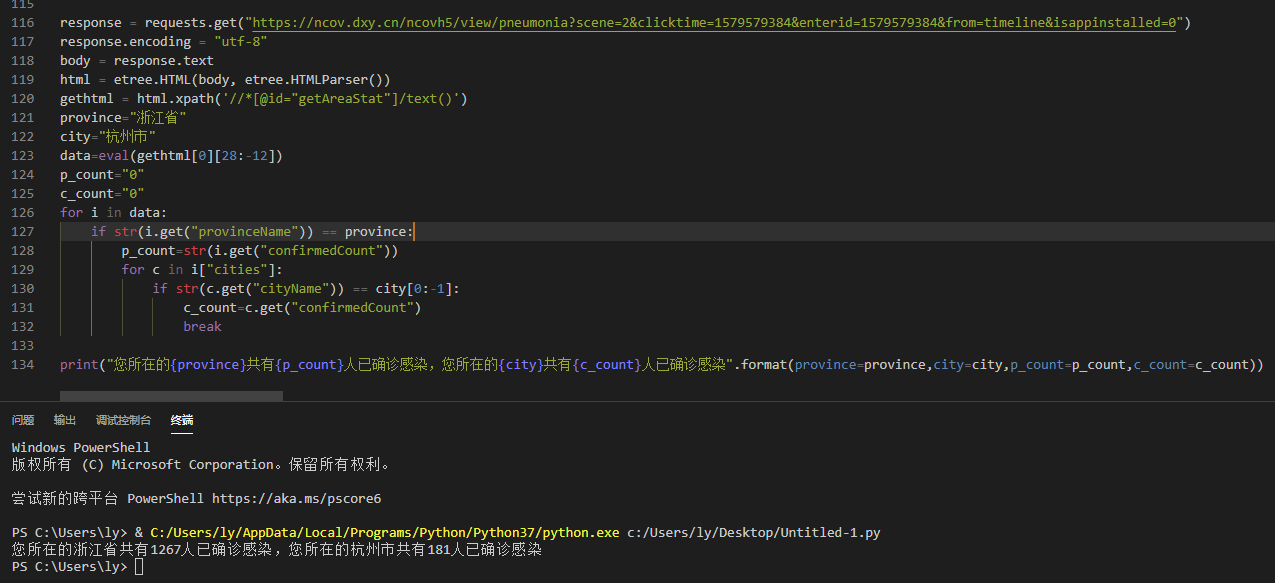
可以发现已经成功了,至于我为什么要用到city[0:-1],是为了对接微信的地理位置数据,这个我会在下一次的博文介绍。结语
这次的难点主要在数据并不是一个单独的json包里,需要我们自己从html代码中获取,并且获取的是js代码,我们还要额外提取其中的数据,总的来说还是难度不大的。
如果有疑问可以在下面评论联系我,那我们下期见~
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!