实战Python爬取B站评论
本文最后更新于:2020年8月24日 中午
前言
本人是一个崩坏三的游戏玩家,大家也都知道官方会因为一些活动,在其他平台发布一些兑换码。为了更方便的获取水晶,就一直有这么个想法,想爬取B站的评论,利用热心网友在官方账号动态下发的评论,来实现获取最新的水晶兑换码。(本思路启迪于酷安一位用网站RSS获取水晶码的大佬,很早以前见过他的帖子,但现在找不到了,这里匿名感谢下)
准备
本次用到的有:
- 浏览器 (本人使用的是Chrome)
- Python3(模块包含:requests,json,time)
本次实战的地址:https://space.bilibili.com/27534330/dynamic
本次实战的目标:爬取下该链接下的所有评论实战开始
获取评论数据包
打开开发者工具,然后通过查看评论来获取我们要的数据包,很好找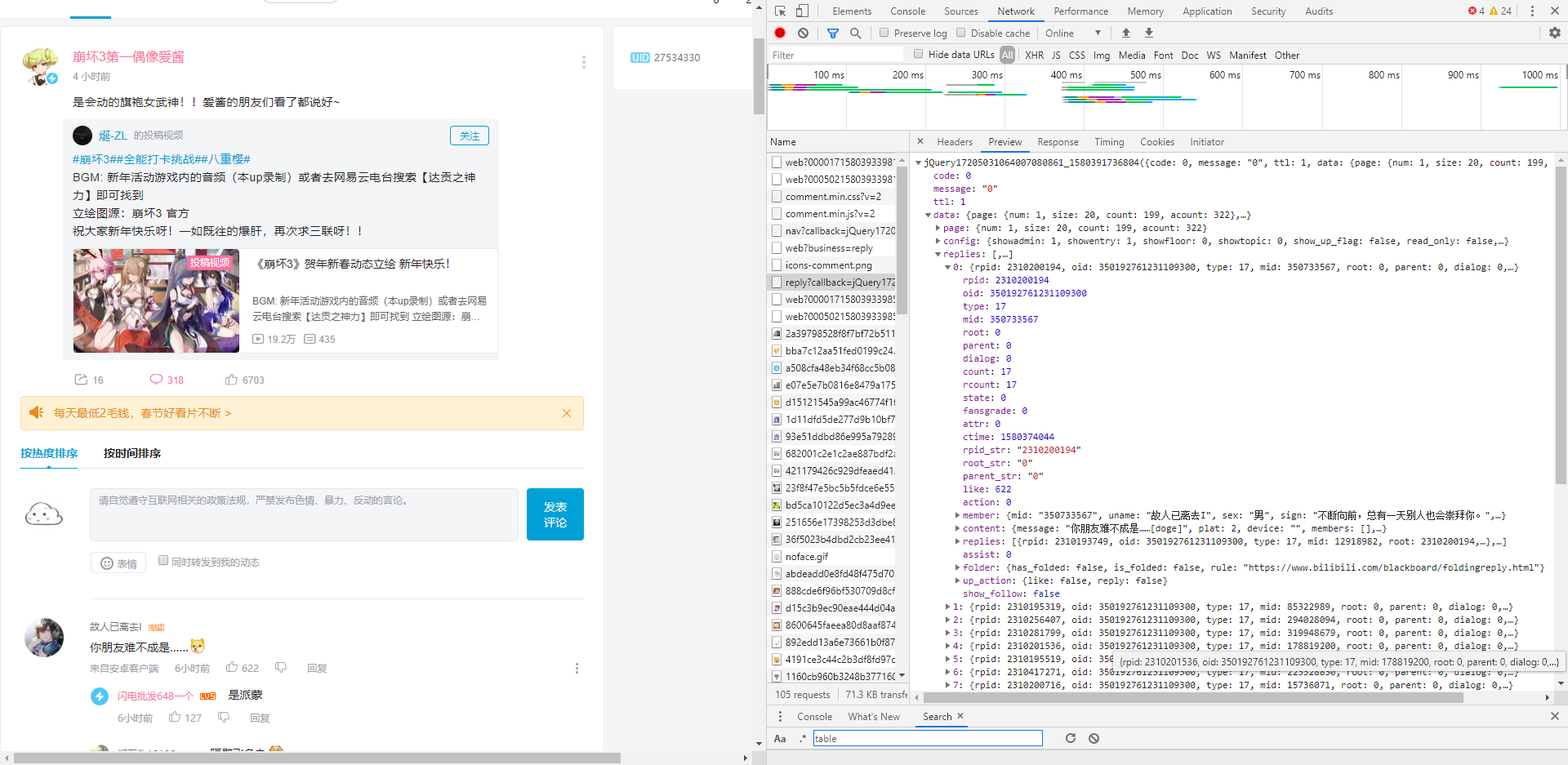
然后我们模拟发送get包来获取数据
1 | |
嗯
*这里用到了两个参数,一个oid对应的是帖子的标识码,获取方法在下方,还有一个参数type是帖子的类型,对应了url里面的type,这里先一笔带过,具体我会在下面的内容中写到。 *
然后我们分析response,通过返回的数据我猜测这是一个jQuery,奈何我没学过,但是不要紧,它的数据类型和json很像,于是我将jQuery的特征码去除,直接当作json处理
1 | |
这段代码就是实现将jQuery特征码去除,变成我们可以处理的json.
然后利用network里的preview,我们可以很清晰的得出评论的目录为/data/hots/(0-5)/content/message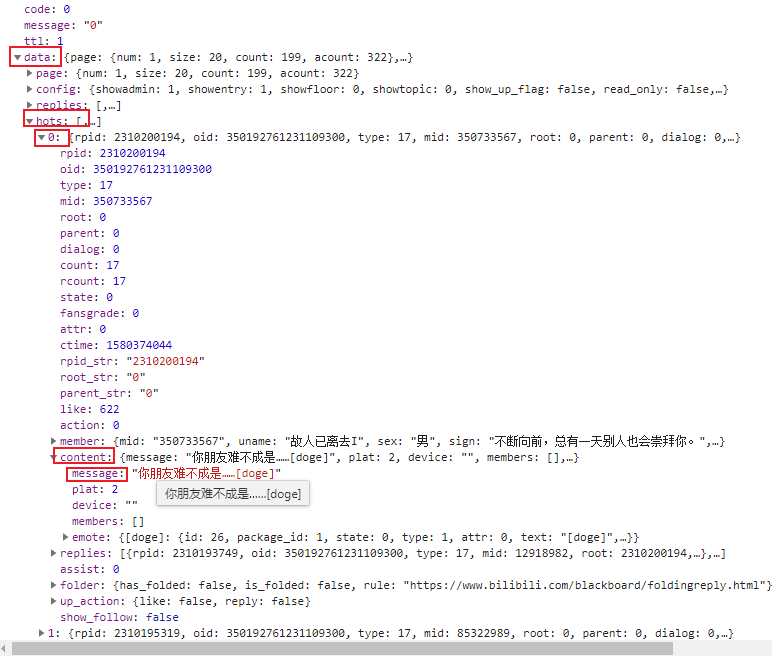
于是写出如下代码
1 | |
到此,我们的获取评论数据功能已经实现(这里我选择的是热评,对应的是hots,也可以自己选择爬取所有的评论)。接下来是获取oid数据来实现批量爬取。
获取动态数据包
首先打开开发者工具,通过刷新来重新获取发送与接受到的数据。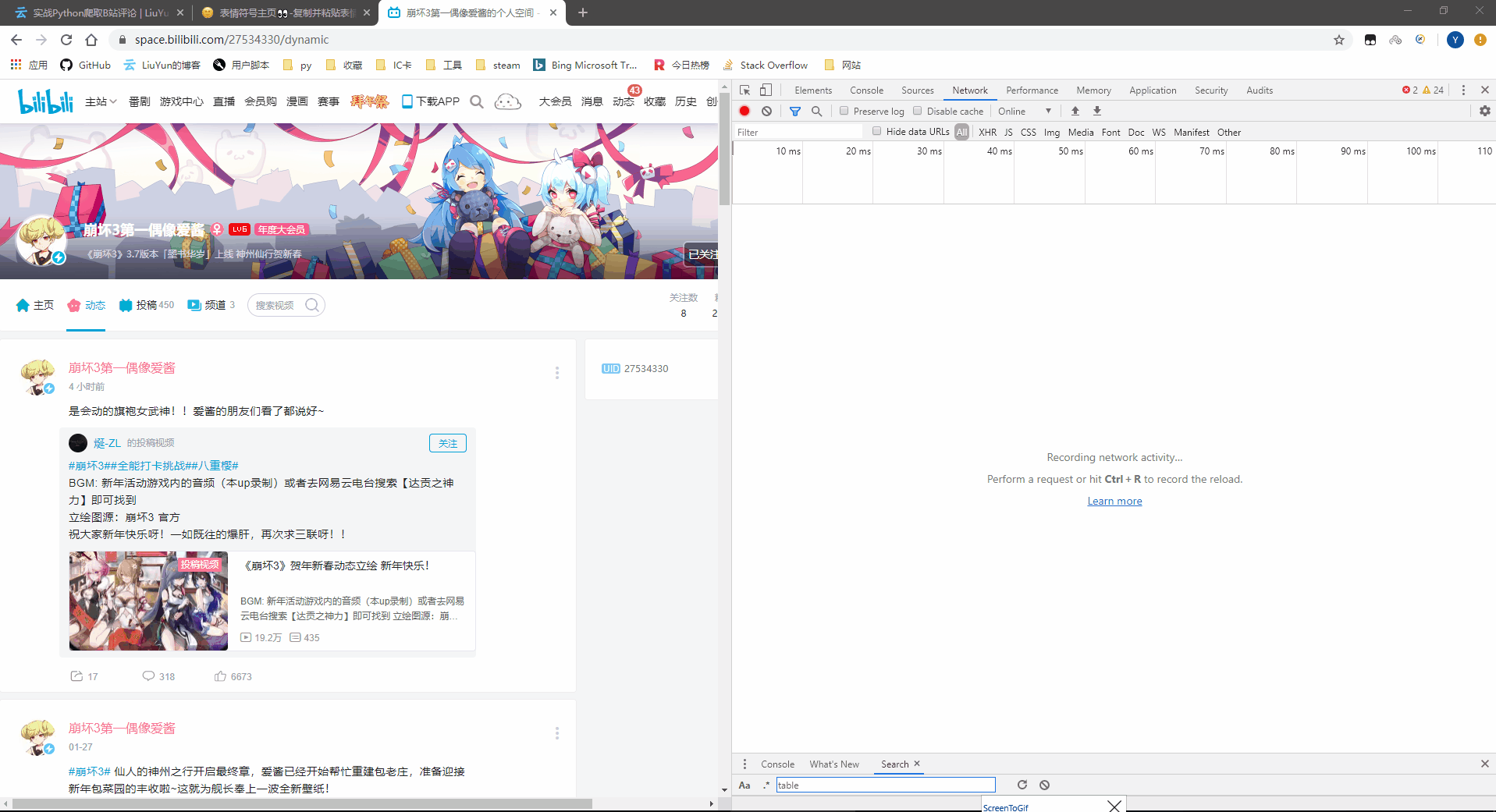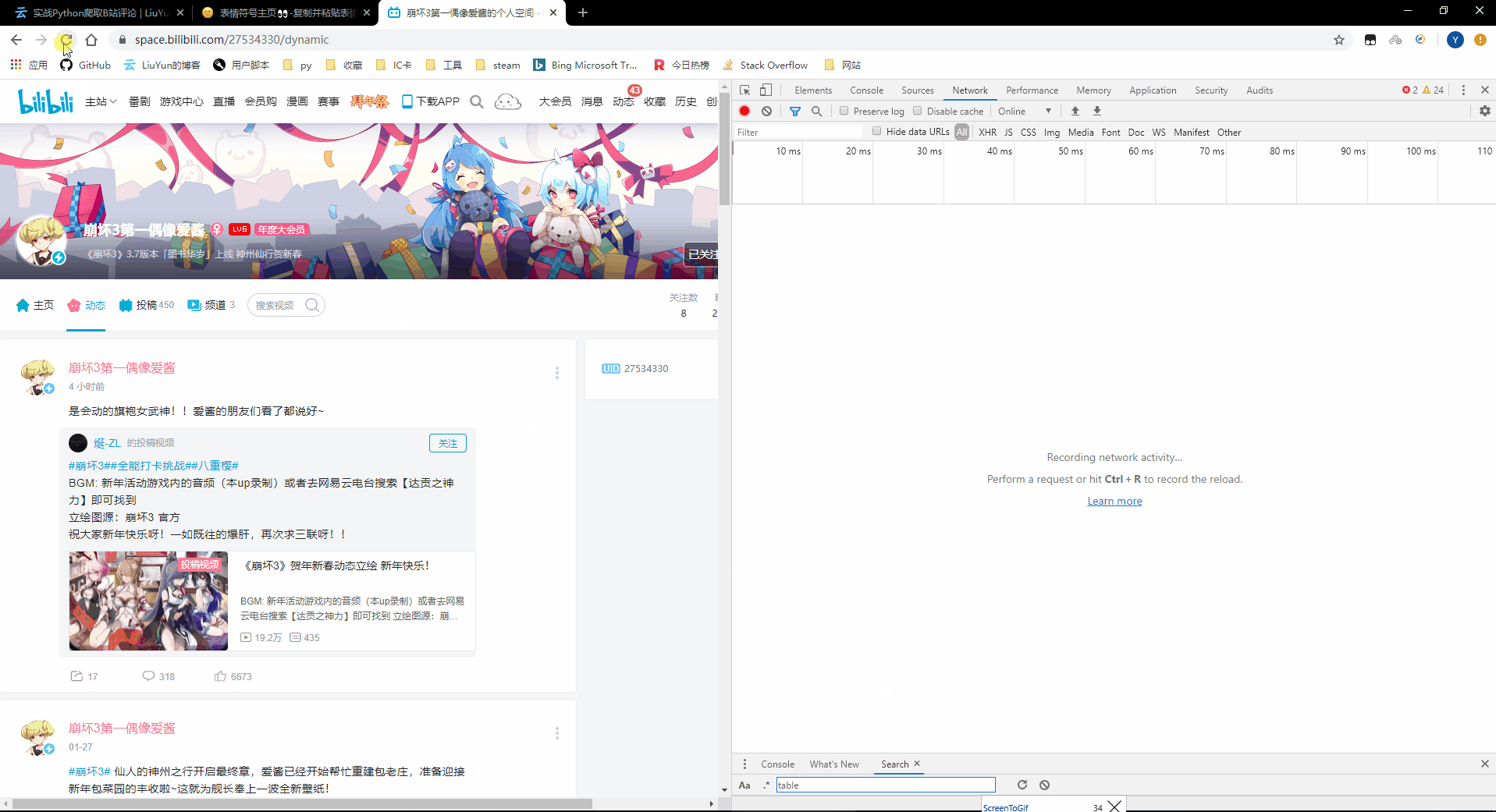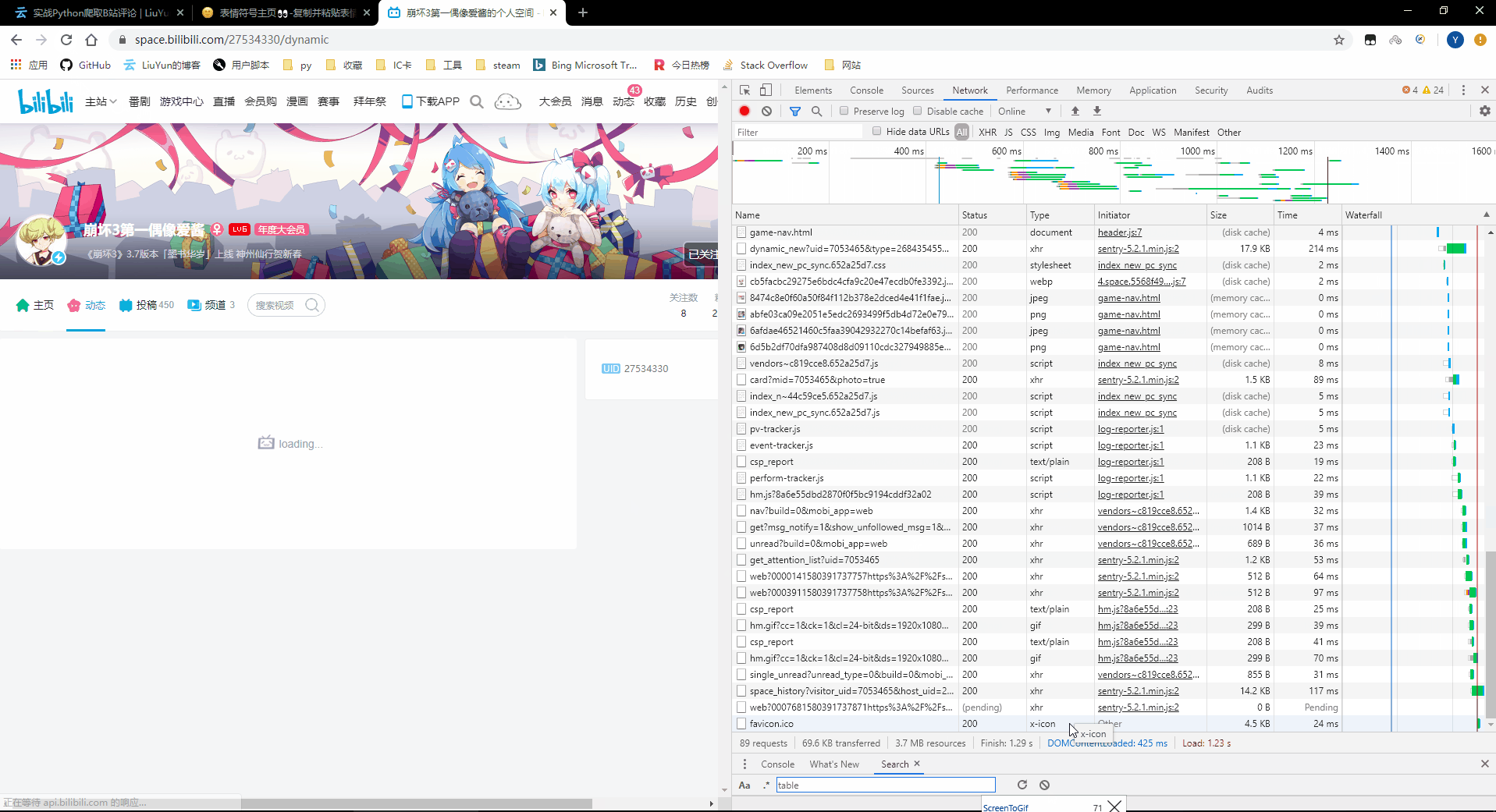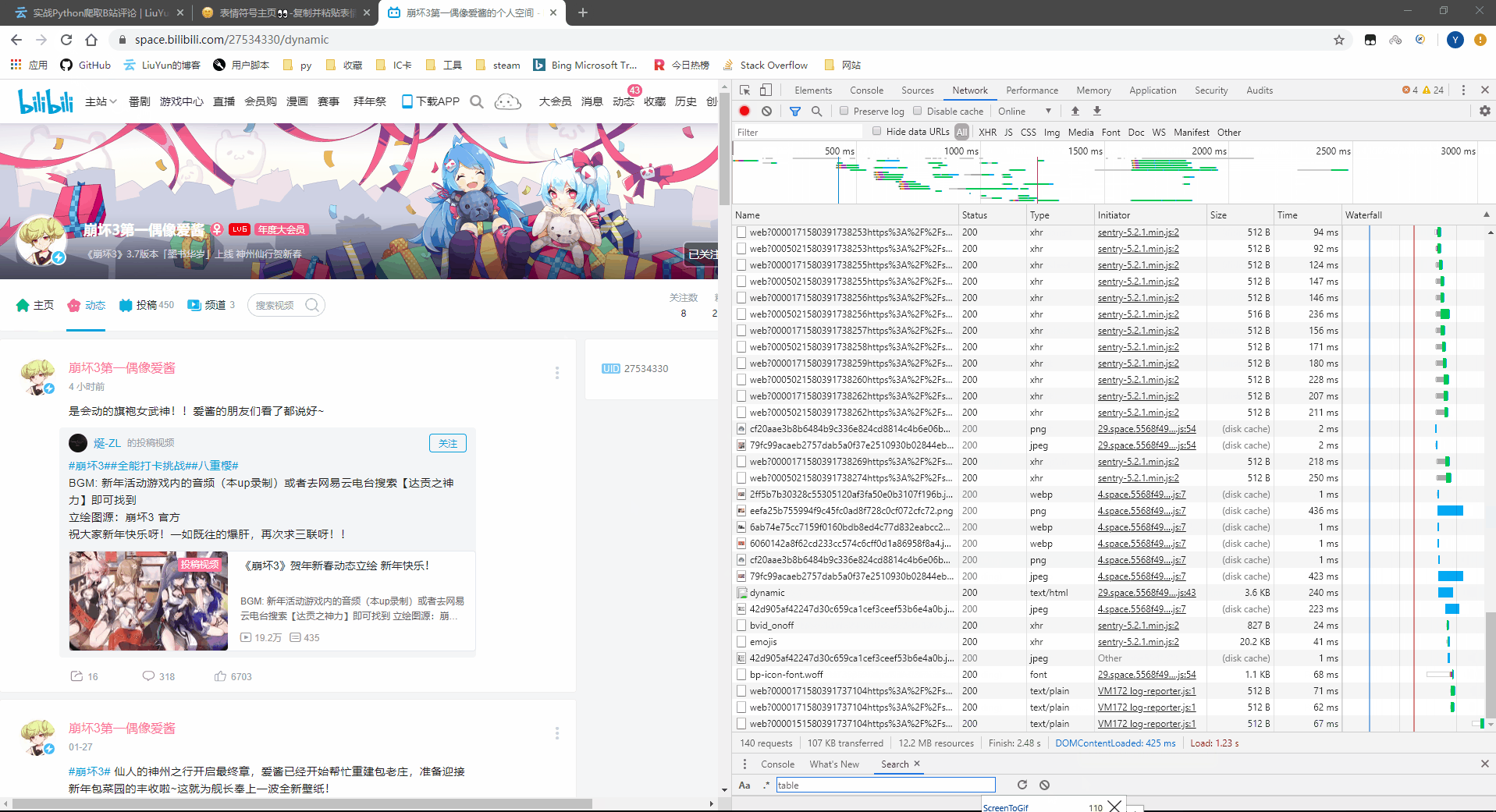
找到我们需要的获取动态的包(小技巧是获取完动态的数据后肯定要向服务器获取动态的一些静态图片,所以在一堆图片的数据包前面找)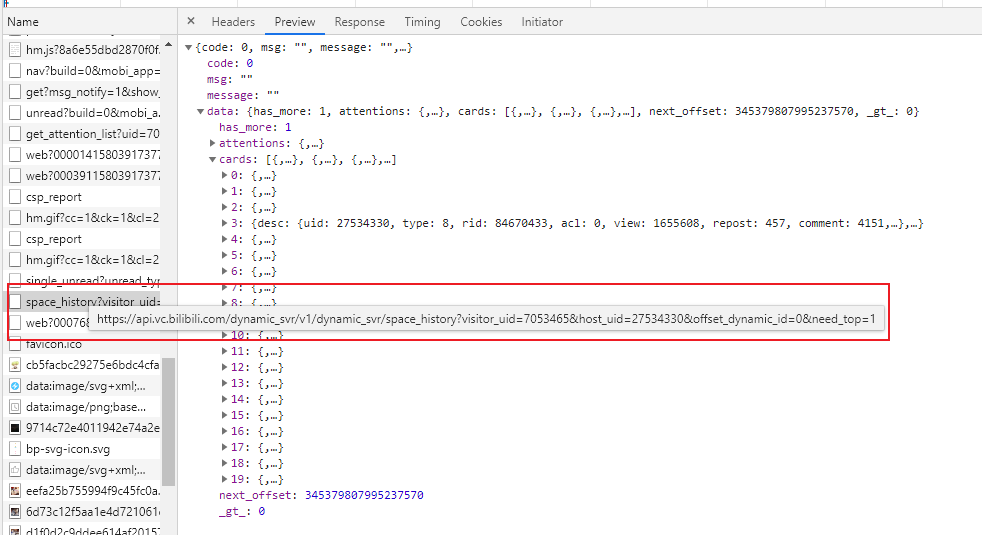
然后将headers复制,按照之前的步骤一样,模拟数据包的发送
写完数据包的发送后,我们开始对发送回来的response进行处理,这里直接通过浏览器的preview进行分析处理(排版挺好的),得出结论我们需要的动态地址的关键信息oid目录为/data/cards/(0-19)/desc/dynamic_id_str(或者rid_str),说实话这里的oid分析卡了我好几天,因为根据动态的类型不同,对应的oid可能是rid,也可能是dynamic_id。
最后我通过穷举法归纳了以下,根据/data/cards/(0-19)/desc/type,2和8对应的是oid是rid,其他的4和1对应的是dynamic。
利用json,故得出以下代码
1 | |
在这里我将oid与type一并返回了,type将在后来的评论获取中再次派上用处。到这里我们其实已经实现了所有功能,只要将上面两个function结合,即可实现爬取所有动态的评论。
type与oid的处理
我觉得这是整个爬取过程的难点,直到这篇文章发布前,我仍未找到有效的解决方法,只能用穷举法。所幸也实现了我们需要的功能。
重新来看看我们评论数据包的地址,发现oid与动态对应的地址对上了,也就是我们之前获取的dynamic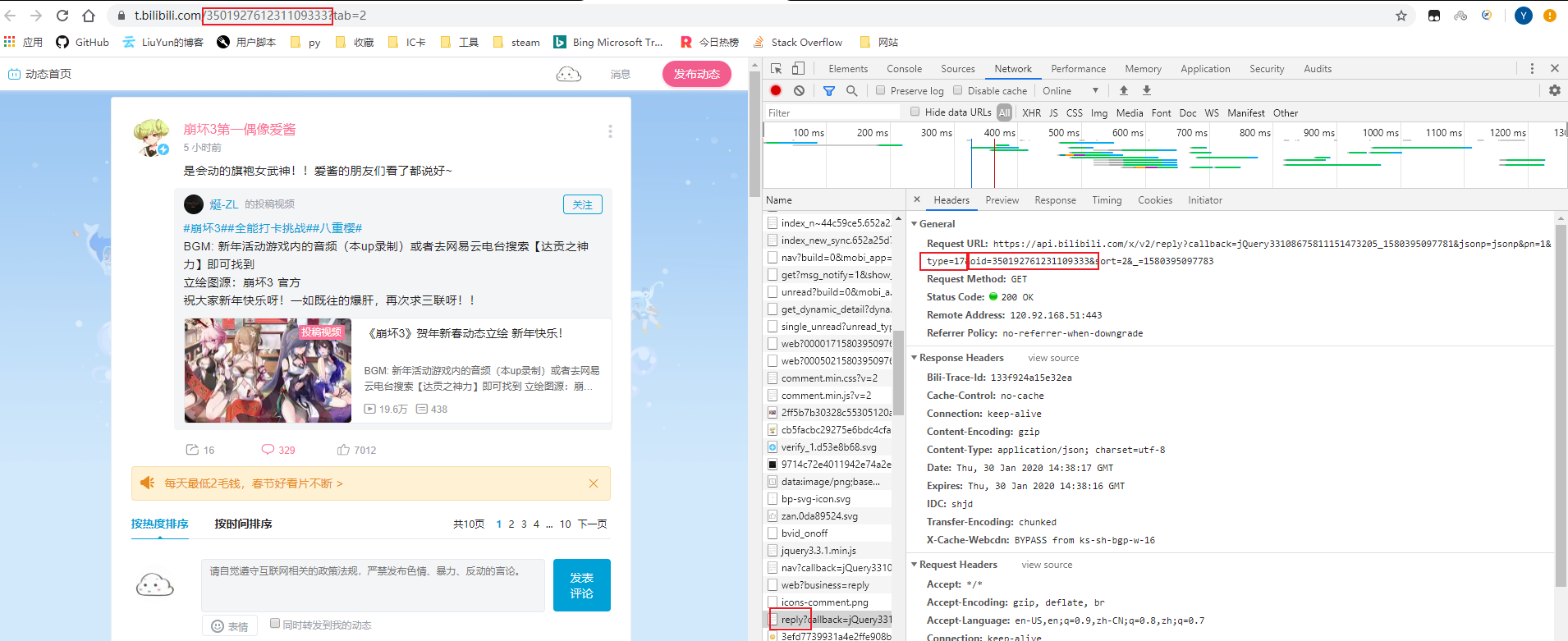
但是也有些动态并不符合这个规律,它的oid没有与动态的地址对应,也就不是dynamic,而是rid。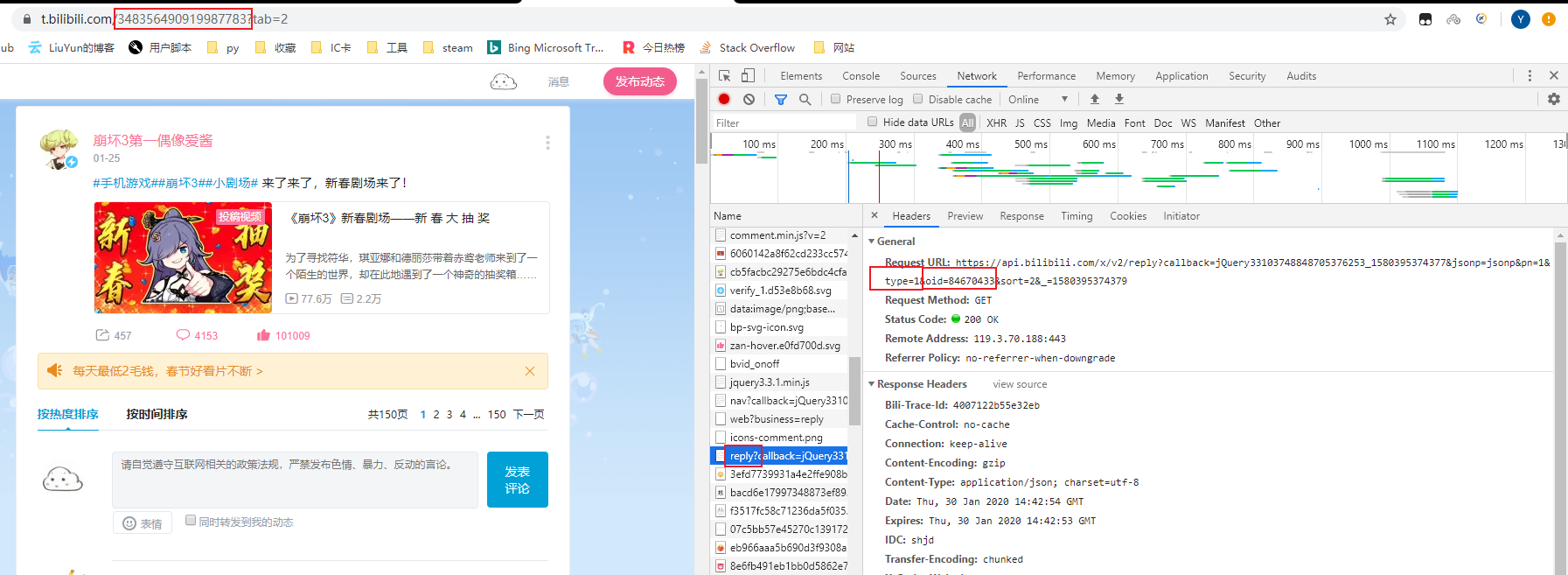
经过穷举的尝试,得出如下结论:
获取的type为2时,评论地址的oid对应rid,地址的type对应11
获取的type为8时,评论地址的oid对应rid,地址的type对应1
获取的type为4时,评论地址的oid对应dynamic,地址的type对应17
获取的type为1时,评论地址的oid对应dynamic,地址的type对应17
于是才得出了上面写的代码。
总结
以下为我在个人尝试中的一些错误,仅供各位参考借鉴:
- 受老旧思想禁锢,我的第一感觉是直接访问动态的地址来获取信息,也就是request-https://space.bilibili.com/27534330/dynamic 。结果错误返回,提示过多的重定向错误于是我通过查找信息,添加参数allow_redirects=False来忽略这个错误,结果是不报错了,但仍然没得到想要的数据,后来才想到通过数据包来获取动态数据
1
requests.exceptions.TooManyRedirects: Exceeded 30 redirects. - jQuery那段我也不清楚是不是jQuery,毕竟没接触过。然后凑巧的是当我将他前面的无关数据剔除掉后,他就是一个非常完美的json数据格式,有点投机取巧的感觉。
- 最后一点就是type和oid了,说实话穷举的方法实在不可取,但也是没办法,他获取的type也与链接里的type并不一致。目前我的猜想是在之前的数据包中有类似的js文件,用来进行对type的处理。
后话
全文共1800余字,感谢你能看到这里,打赏这种不可能的我也就不说了。成品文件我已放在了我的GitHub上,如果有什么疑问或者我的代码有何问题,请在下方的评论区回复。
因为某些原因已经删除了该项目的GitHub仓库,所以直接在下面附上代码。需要注意的是本文件在获取评论的基础上增加了获取崩坏三兑换码的功能(尚未完善),但是获取评论的代码以自定义函数的方式独立出现,所以仍不影响阅读学习。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117# -*- coding: utf-8 -*-
import requests,json,time,re
dhm=[]
def get_comment(oid=str,types=int):
headers_small={
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Connection':'keep-alive',
'Cookie':r'',
'Host':'api.bilibili.com',
'Referer':'https://space.bilibili.com/27534330/dynamic',
'Sec-Fetch-Mode':'no-cors',
'Sec-Fetch-Site':'same-site',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
#requests.exceptions.TooManyRedirects: Exceeded 30 redirects. 太多重定向,使用allow_redirects=False 302重定向页面
if types==2:
rsp=requests.get(url="https://api.bilibili.com/x/v2/reply?callback=jQuery172017694877061996372_1580287236452&jsonp=jsonp&pn=1&type=11&oid={0}&sort=2&_=1580287547926".format(oid),headers=headers_small,allow_redirects=False)
elif types==8:
rsp=requests.get(url="https://api.bilibili.com/x/v2/reply?callback=jQuery172017694877061996372_1580287236452&jsonp=jsonp&pn=1&type=1&oid={0}&sort=2&_=1580287547926".format(oid),headers=headers_small,allow_redirects=False)
elif types==4:
rsp=requests.get(url="https://api.bilibili.com/x/v2/reply?callback=jQuery172017694877061996372_1580287236452&jsonp=jsonp&pn=1&type=17&oid={0}&sort=2&_=1580287547926".format(oid),headers=headers_small,allow_redirects=False)
elif types==1:
rsp=requests.get(url="https://api.bilibili.com/x/v2/reply?callback=jQuery172017694877061996372_1580287236452&jsonp=jsonp&pn=1&type=17&oid={0}&sort=2&_=1580287547926".format(oid),headers=headers_small,allow_redirects=False)
else:
print("types error"+str(types))
#print(rsp.status_code)
try:
rsp_json=json.loads(rsp.text[42:-1])
except:
pass
'''
with open("D:/py/123.htm","w",encoding='utf-8')as f:
f.write(rsp.text[41:-1])
#rsp_xpath = selector.xpath('//div[@id="app"]/div[@class="s-space"]/div/div/div/div/div/div')
rsp_json=json.loads(rsp.text)
rsp_jsonpath=jsonpath.jsonpath(rsp_json,'$..message')
print(rsp_jsonpath)
'''
'''
for i in range(len(rsp_json["data"]["hots"])):
print(rsp_json["data"]["hots"][i]["replies"][i]["content"]["message"])
评论中的评论
'''
try:
for i in range(len(rsp_json["data"]["hots"])):
print(str(i+1)+": "+rsp_json["data"]["hots"][i]["content"]["message"])
try:
for x in re.findall("([a-z0-9A-Z]{10,17})",rsp_json["data"]["hots"][i]["content"]["message"]):
dhm.append(x)
except:
pass
'''
try:
for j in range(len(rsp_json["data"]["hots"][i]["replies"])):
print(" "+rsp_json["data"]["hots"][i]["replies"][j]["content"]["message"])
except:
pass
'''
print("_______________________________________")
except:
pass
def get_dynamic():
dynamic_headers={
'Accept':'application/json, text/plain, */*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Connection':'keep-alive',
'Cookie':r'',
'Host':'api.vc.bilibili.com',
'Origin':'https://space.bilibili.com',
'Referer':'https://space.bilibili.com/27534330/dynamic',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-site',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
dynamic=requests.get(url="https://api.vc.bilibili.com/dynamic_svr/v1/dynamic_svr/space_history?visitor_uid=7053465&host_uid=27534330&offset_dynamic_id=0&need_top=1",headers=dynamic_headers)
dynamic_json=json.loads(dynamic.text)
comment_list=[]
comment_type_list=[]
try:
for i in range(len(dynamic_json["data"]["cards"])):
comment_type=dynamic_json["data"]["cards"][i]["desc"]["type"]
if comment_type == 2 or comment_type==8 :
comment_list.append(dynamic_json["data"]["cards"][i]["desc"]["rid_str"])
else:
comment_list.append(dynamic_json["data"]["cards"][i]["desc"]["dynamic_id_str"])
comment_type_list.append(comment_type)
except:
pass
return([comment_list,comment_type_list])
if __name__ == "__main__":
t=time.time()
comments=[]
comments_type=[]
comments=get_dynamic()[0]
comments_type=get_dynamic()[1]
for x,y in zip(comments,comments_type):
print(str(x)+" "+str(y))
get_comment(x,y)
#time.sleep(3)
print(time.time()-t)
print(dhm)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!