流式下载-Python的下载进阶
本文最后更新于:2021年1月31日 下午
常规下载
近年来,Python常常与爬虫相挂钩,许多我身边的朋友听说Python甚至直接将它与爬虫划上了等号。仅仅通过几句代码,我们就可以用它来爬小说,来下载电影,来保存许多图片。
1 | |
上面这4句代码,就实现了最基础的下载功能。日常使用中我们往往只需要遵循这个框架,偶尔补上个UA,或者加个登录的cookie,总之万变不离其中。普通的下载图片肯定没什么问题的,但是当我们下载一个比较大的视频时,就会发现内存占用很大。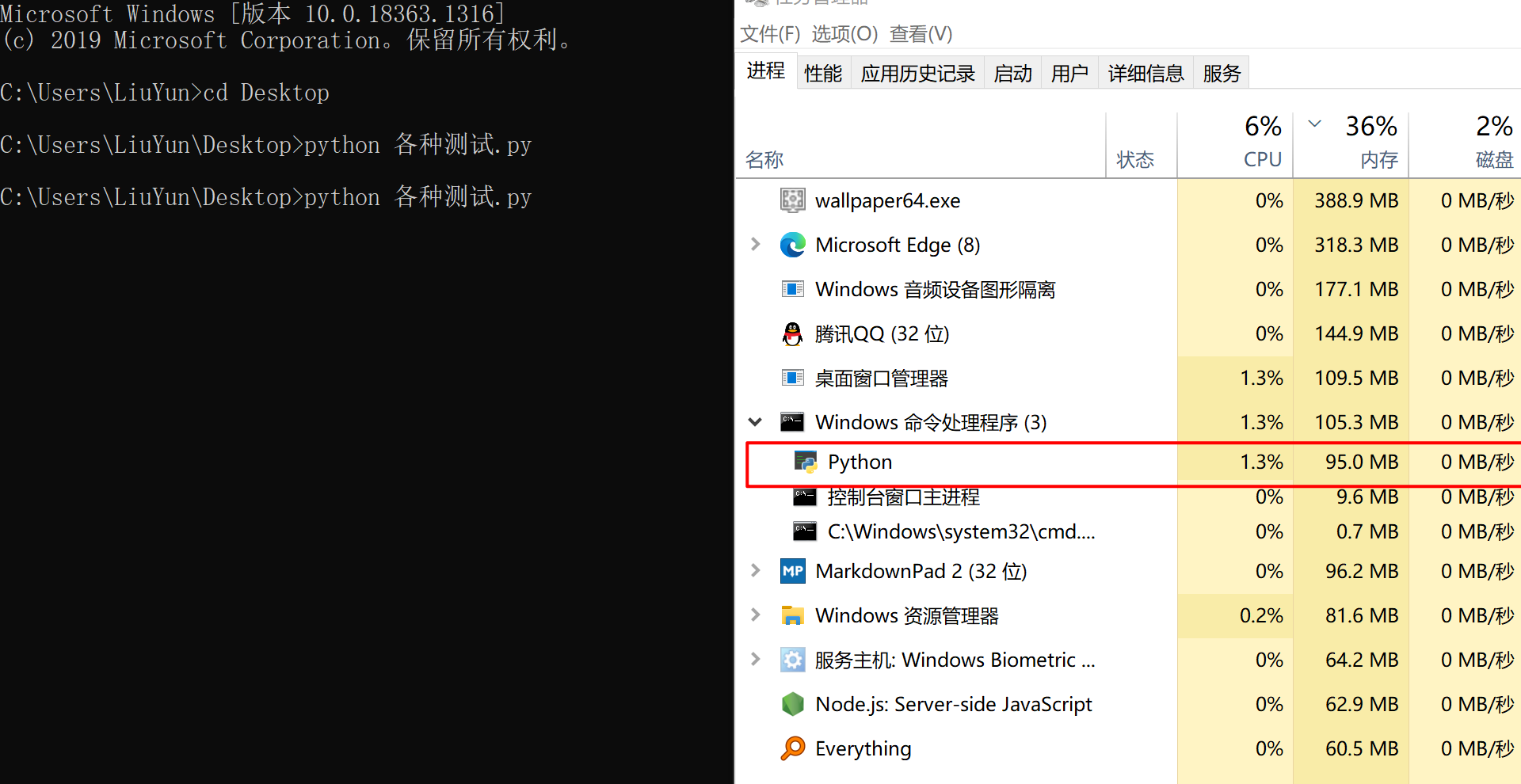
就像上面这样,一下子就占用了解决100MB内存。这要是配置低点的电脑可就直接吃不消了啊。
问题解析
试多了我们就能发现,内存占用的大小与我们下载的文件的大小基本一致。其实很好解释,requests模块的get方法,获取了所有的相关数据,并将它返回保存在rsp这个变量里。而变量又是存放在内存堆里的,自然内存就占去了一整个视频的大小。
那这可怎么办呢,我们对数据的读写肯定得先通过内存/缓存,再写入硬盘。既然一次性内存占用过大,那我们就分段下载,一段段下,一段段写。
解决方案——流式下载
1 | |
get方法中的stream参数,默认为 False 。指定为 True 时,只有当我们调用rsp.content时,下载才会开始。
而response类的iter_content方法,则会像我们所想的那样,获取一段content。利用循环,我们就可以实现一段段的拿,一段段的写。里面的参数chunk_size为单次最多拿到的数据大小(即上限,但不一定能达到),单位为字节。可以根据自己的带宽与内存大小进行调节。
以下是requests模块中对于该方法的注释:
Iterates over the response data. When stream=True is set on the request, this avoids reading the content at once into memory for large responses. The chunk size is the number of bytes it should read into memory. This is not necessarily the length of each item returned as decoding can take place.
至此,我们便解决了这个令人头疼的问题,来看看效果吧。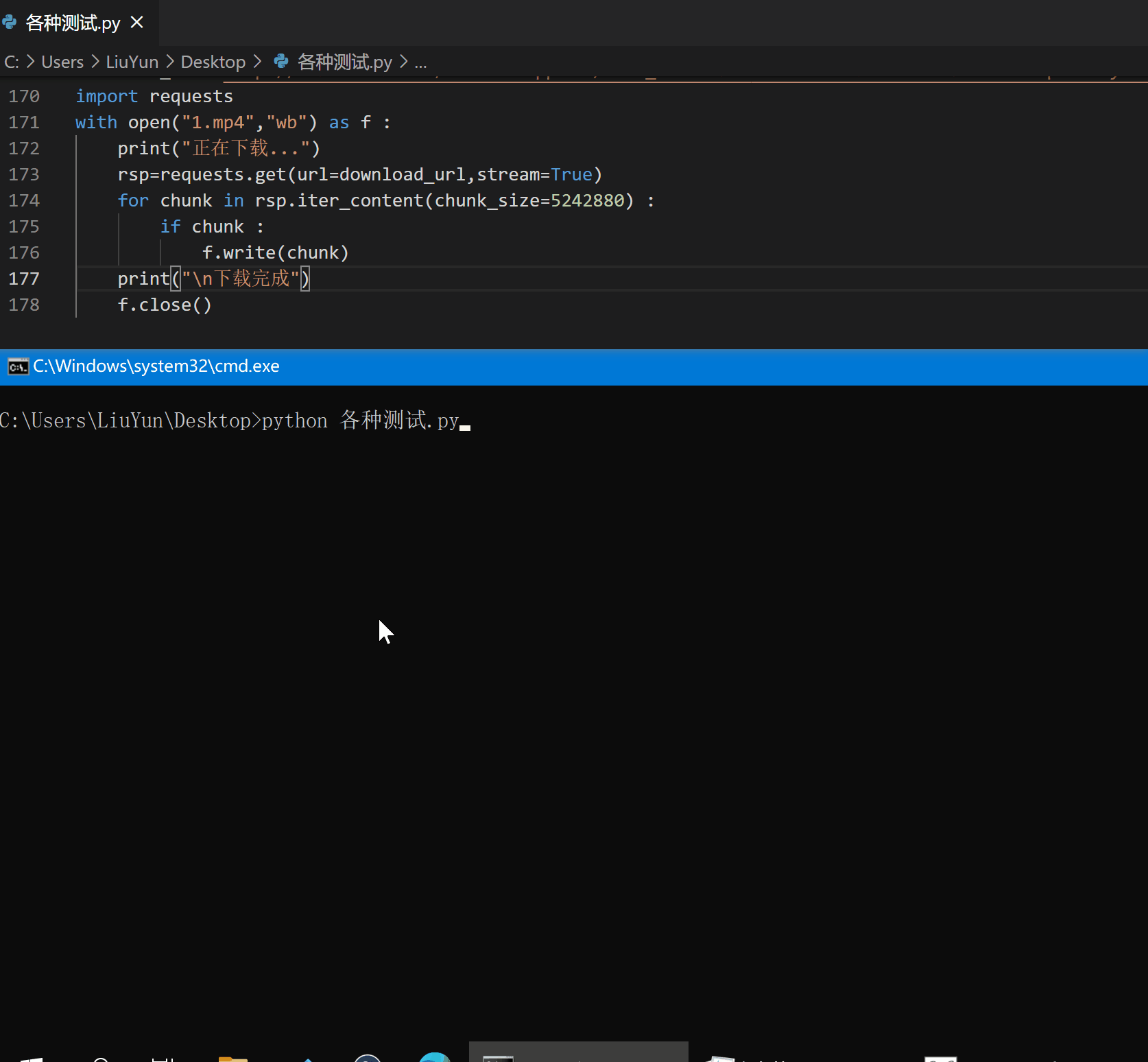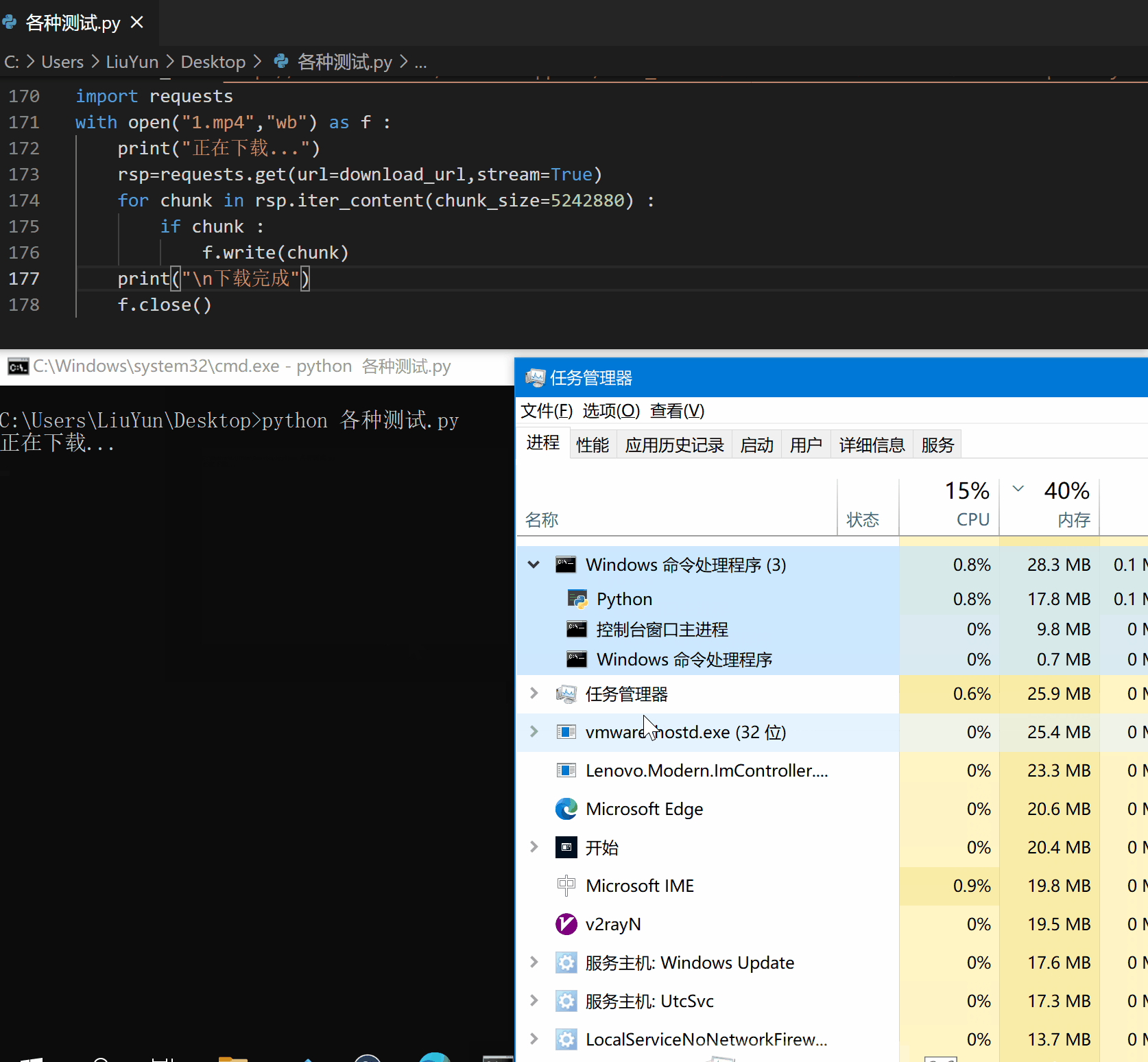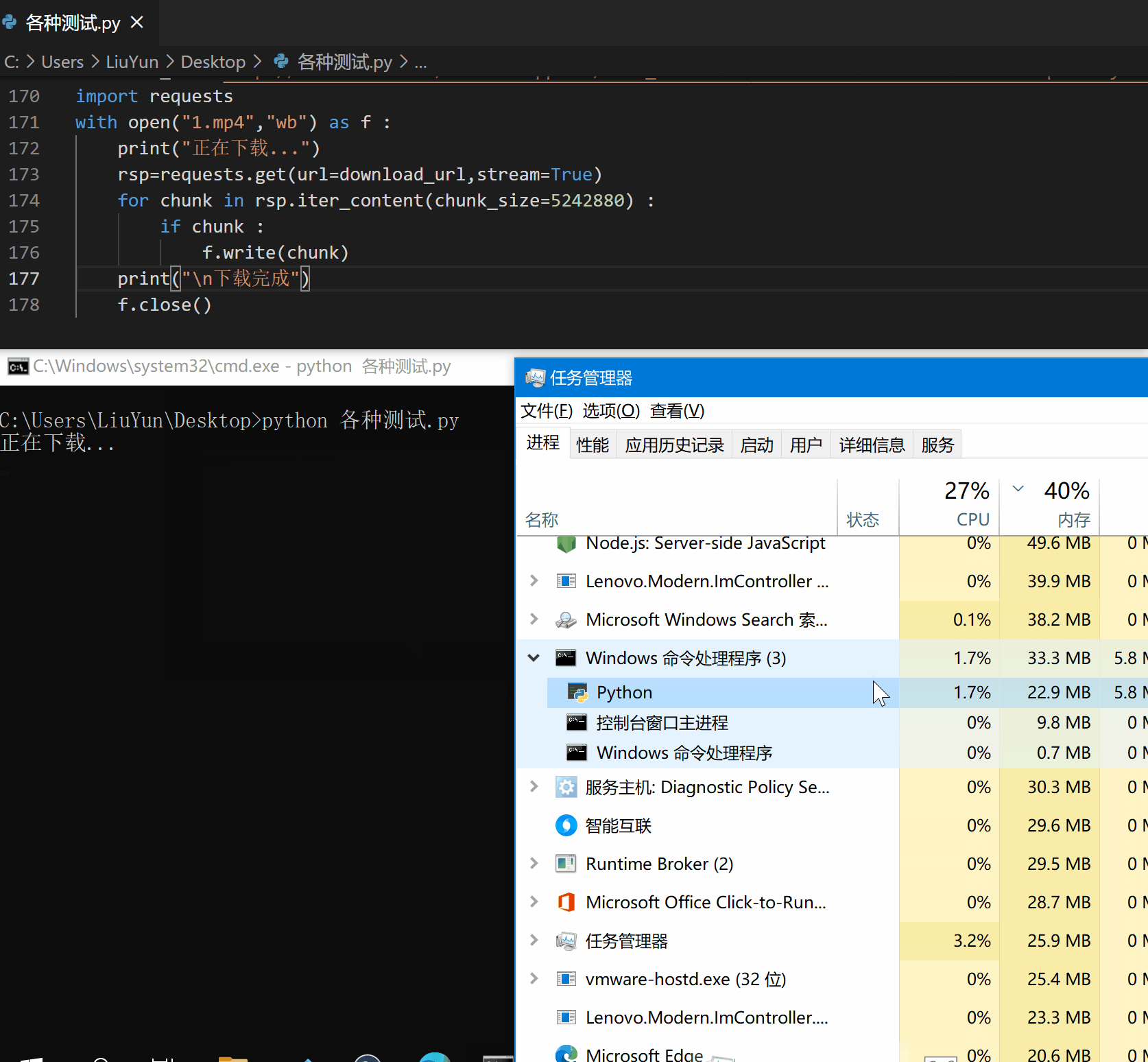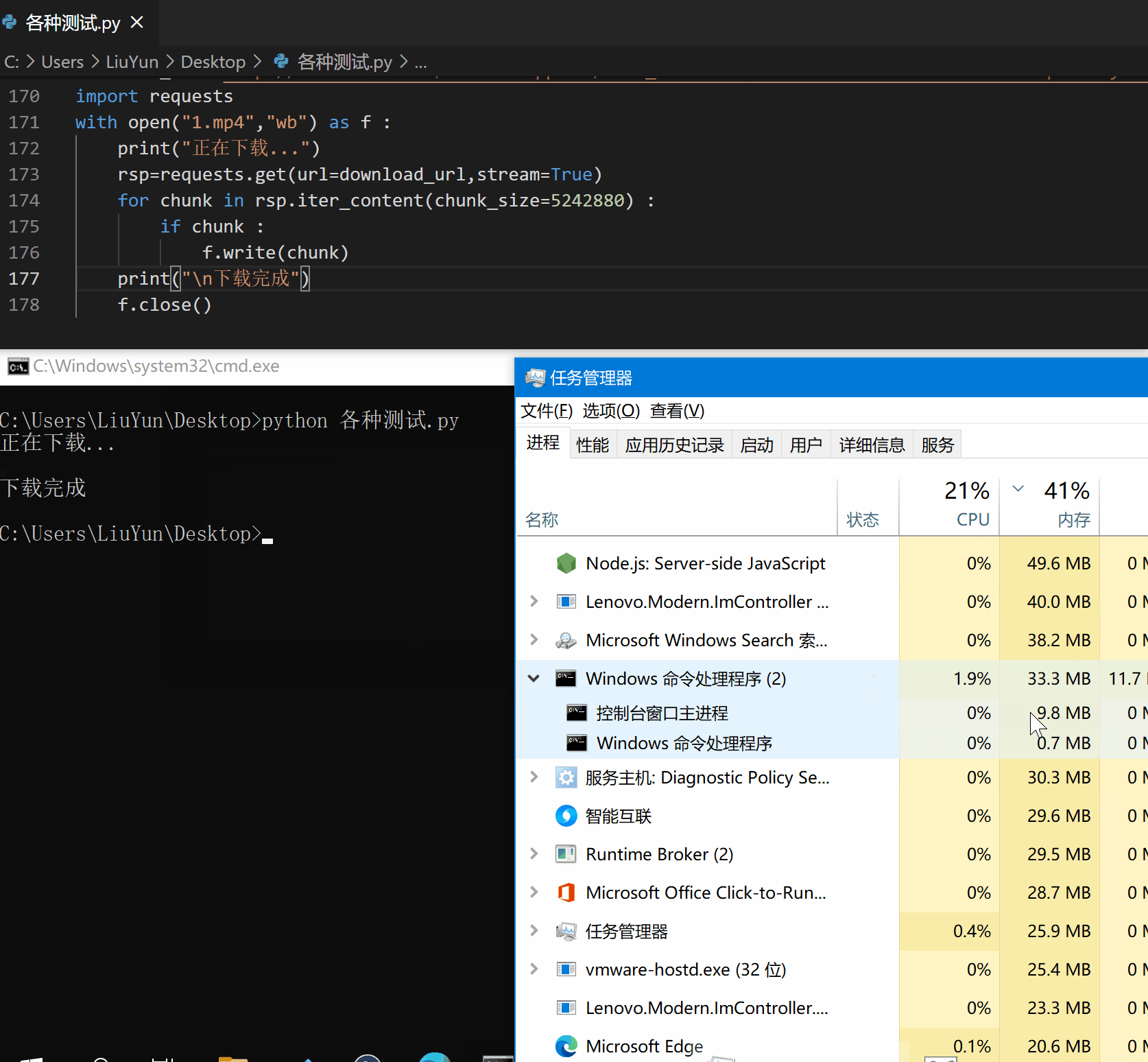
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!