本文最后更新于:2021年1月30日 下午
前言
作为一个刚步入大学的新生,跟全国广大的大学生一样,也受到了来自各种学习软件的迫害,“超星”就是其中之一。因为疫情及各种学校当地原因,我们学校决定于十月开学,于是也就多了一个多月的线上学习时间。通过各种腾讯课堂,钉钉,腾讯会议,学习通等等进行网络授课。期间也遇到了各种宣传代刷网课的,本着以锻炼自己爬虫实力为目的,在闲暇之余开始研究超星的网络协议(主要上面有好多学习视频任务需要完成)。
在此也声明一下,本教程仅供学习,请勿用于非法商业用途。刷课一时爽,但也不要忘了掌握好知识,杜绝挂科。
正文
登录
网页分析
超星平台的旧版登录是需要验证码的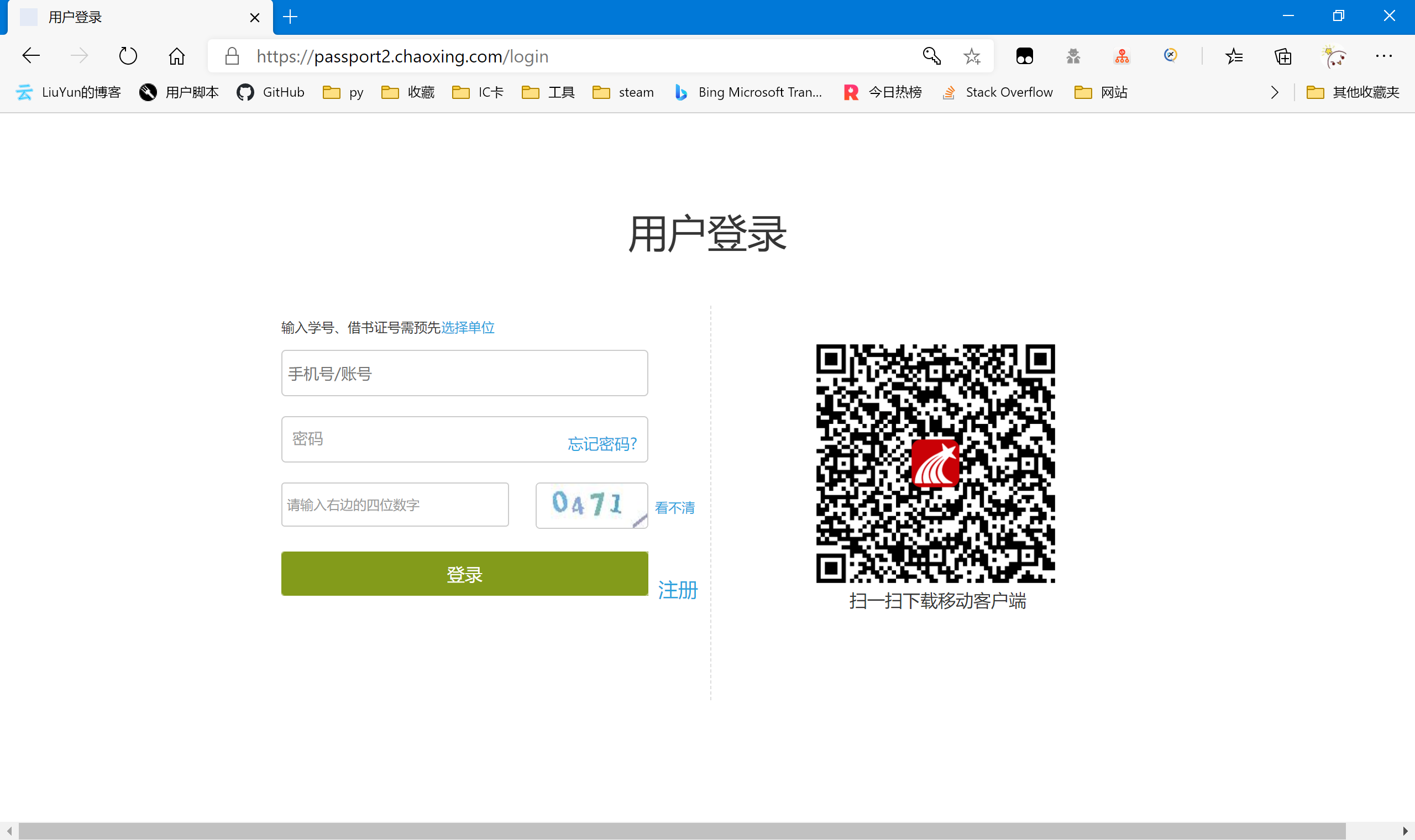
然而通过新版进去却不需要直接输入验证码(尚未测试过多次密码错误后是否会出现验证码)
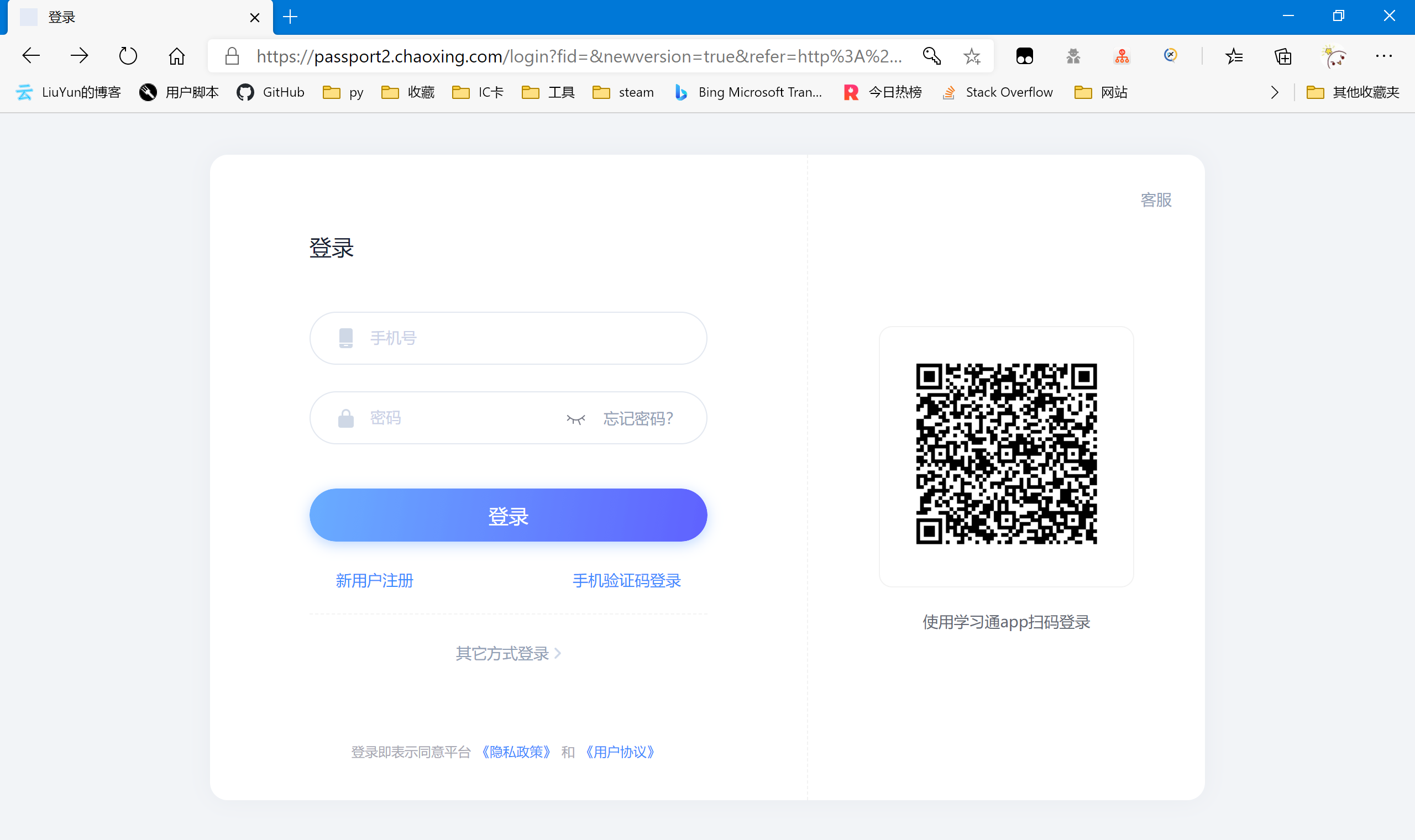
本着能简化就简化的理念(主要是懒),我们直接抓取这个新版的登录页面。https://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com
尝试登录,老套路了,避免登录成功后跳转出现很多包,我们直接输入错误的登录信息。结果很符合我们的预期,只多出了一个包
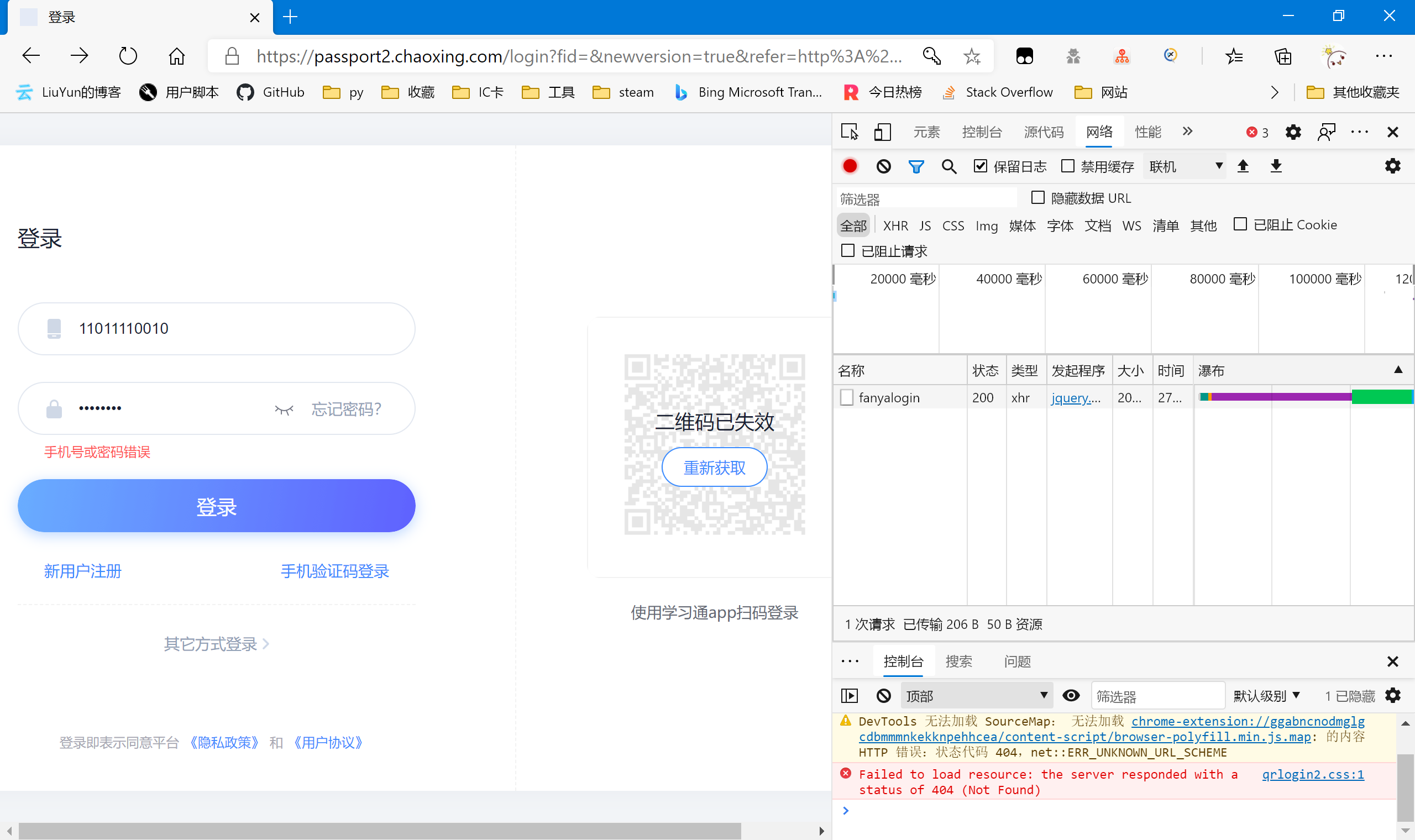
查看预览,正好是提示我们的“用户名或密码错误”,我们查看提交的表单,一个个来分析。
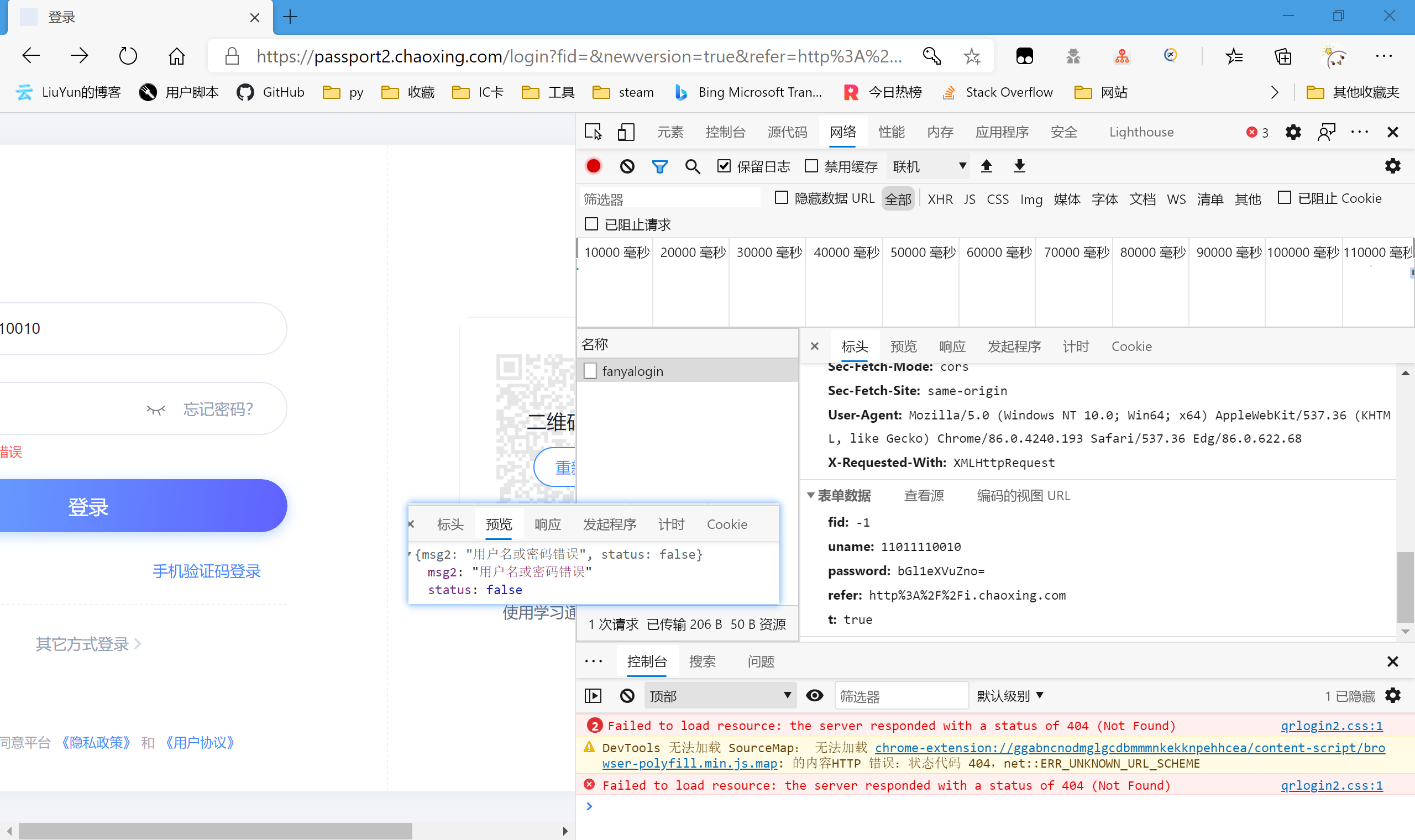
| fid: -1
uname: 11011110010
password: bGl1eXVuZno=
refer: http%3A%2F%2Fi.chaoxing.com
t: true
|
不管fid,-1应该是一个常量。uname正好是我们输入的手机号。password结尾有“=”,我们大胆猜测是base64编码
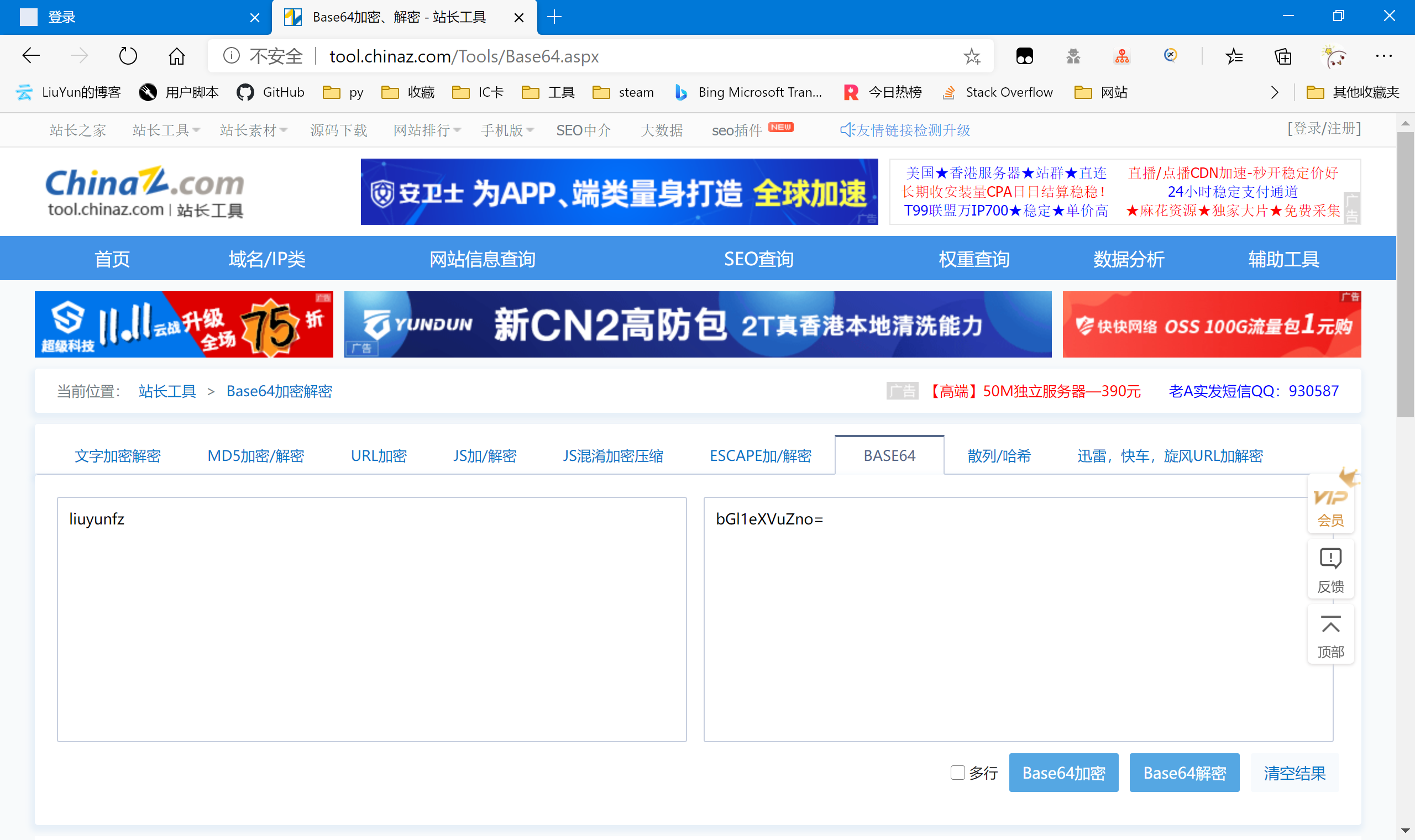
正好是我们输入的密码,那么password也搞定了。t是一个布尔值,也作为常量,refer我就不多解释了,也把它作为常量吧。
代码撰写
照着我们的分析,我们尝试利用python代码模拟我们的登录操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import requests,base64
def sign_in(username:str,password:str):
url="https://passport2.chaoxing.com/fanyalogin"
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection':'keep-alive',
'Content-Length':'95',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'',
'Host':'passport2.chaoxing.com',
'Origin':'https://passport2.chaoxing.com',
'Referer':'https://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36 Edg/86.0.622.68',
'X-Requested-With':'XMLHttpRequest'
}
data="fid=-1&uname={0}&password={1}&refer=http%253A%252F%252Fi.chaoxing.com&t=true".format(username,base64.b64encode(password.encode()).decode())
print(base64.b64encode(password.encode()).decode())
rsp=requests.post(url=url,headers=headers,data=data)
print(rsp.text,rsp.status_code)
|
调试一下,我这里把私密信息打了马赛克,但不影响看出成功。
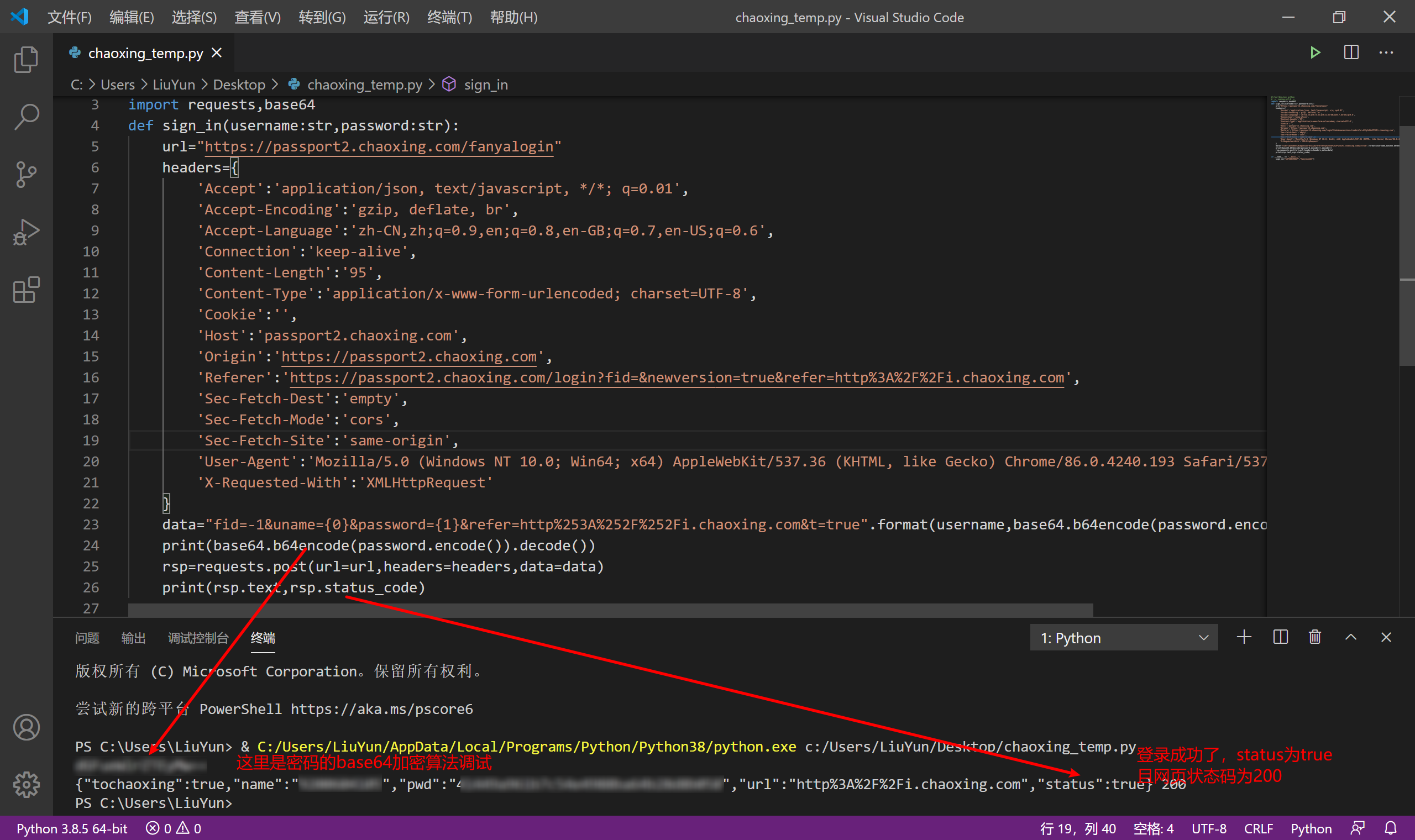
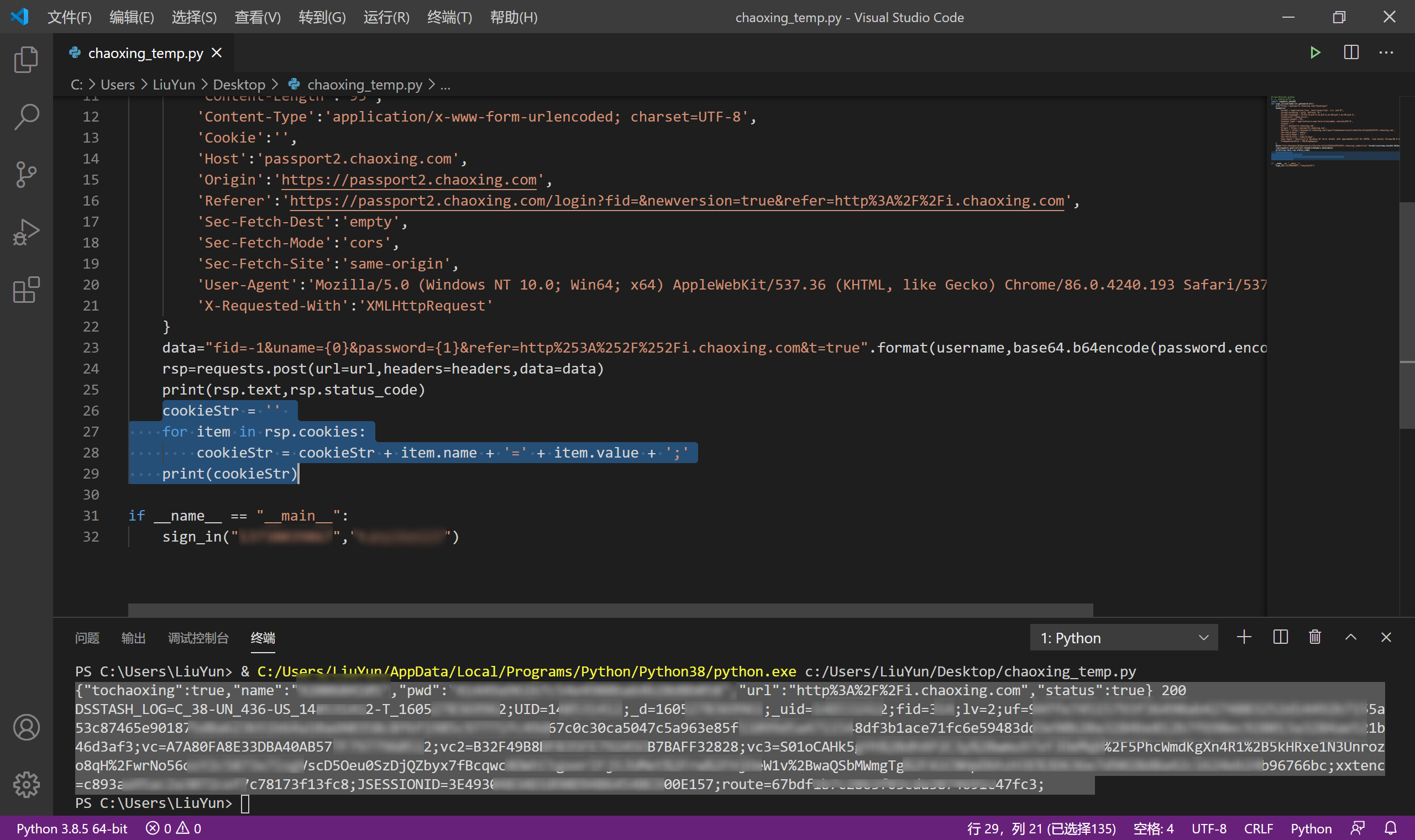
为了后续内容的顺利进行,这边我们再把登录成功的cookie记录下来
| cookieStr = ''
for item in rsp.cookies:
cookieStr = cookieStr + item.name + '=' + item.value + ';'
print(cookieStr)
|
获取课程
网页分析
抓取课程信息
因为不能确定个人空间里面的课程内容是通过json获取数据在本地渲染的还是服务器就渲染好后传给用户的。所以我们还是抓包看看。
查找我们的课程,发现在源代码里并没有找到,所以大概率是第一种可能,所以我们尝试往下找传递课程数据的json包。
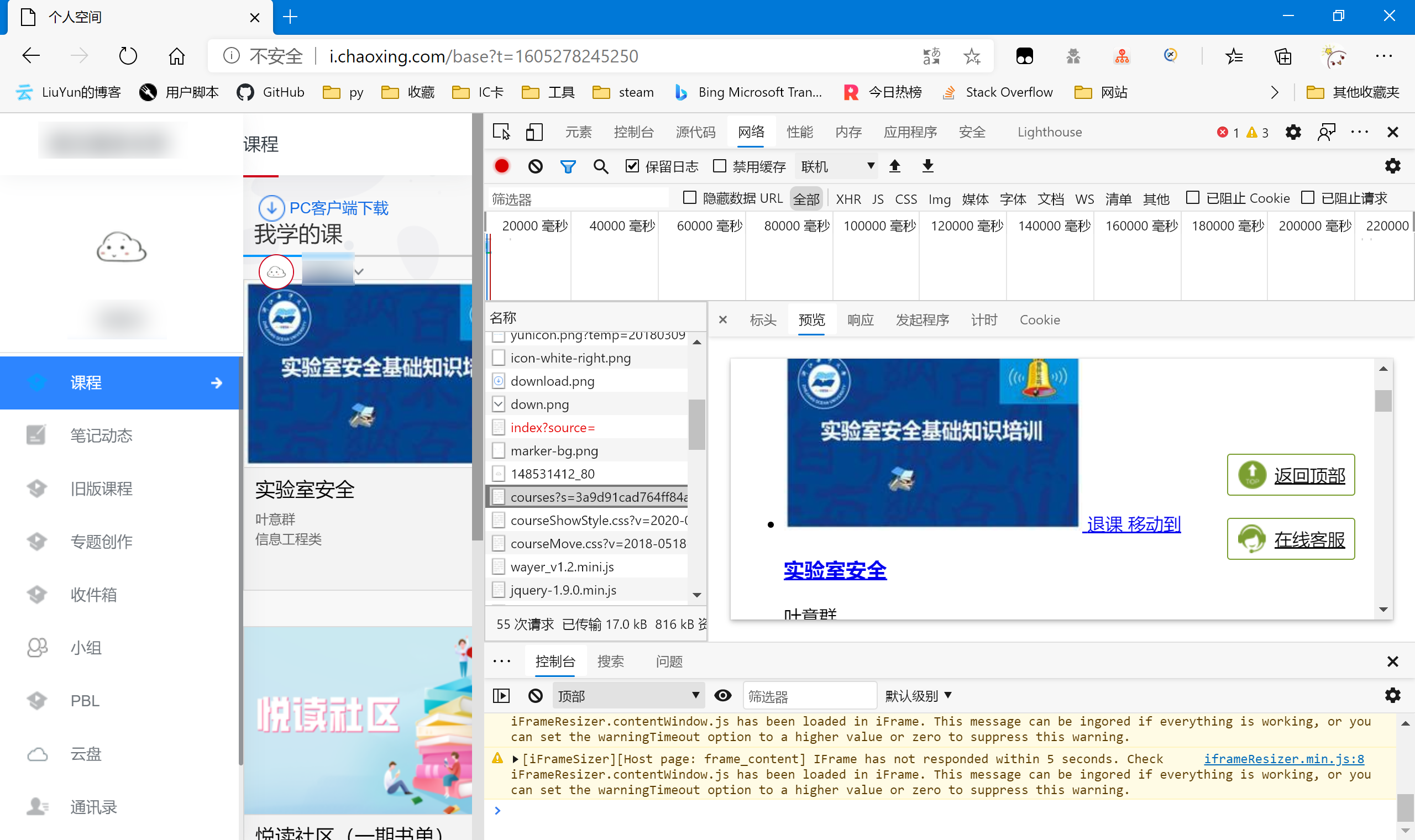
可以看到,成功找到了我们要的数据包,可惜并不是我们想要的json包,但问题也不大,只是增加了我们代码解析时的复杂度。然后具体看我们抓到的这个课程数据包,请求方式为get,唯一麻烦的是参数s
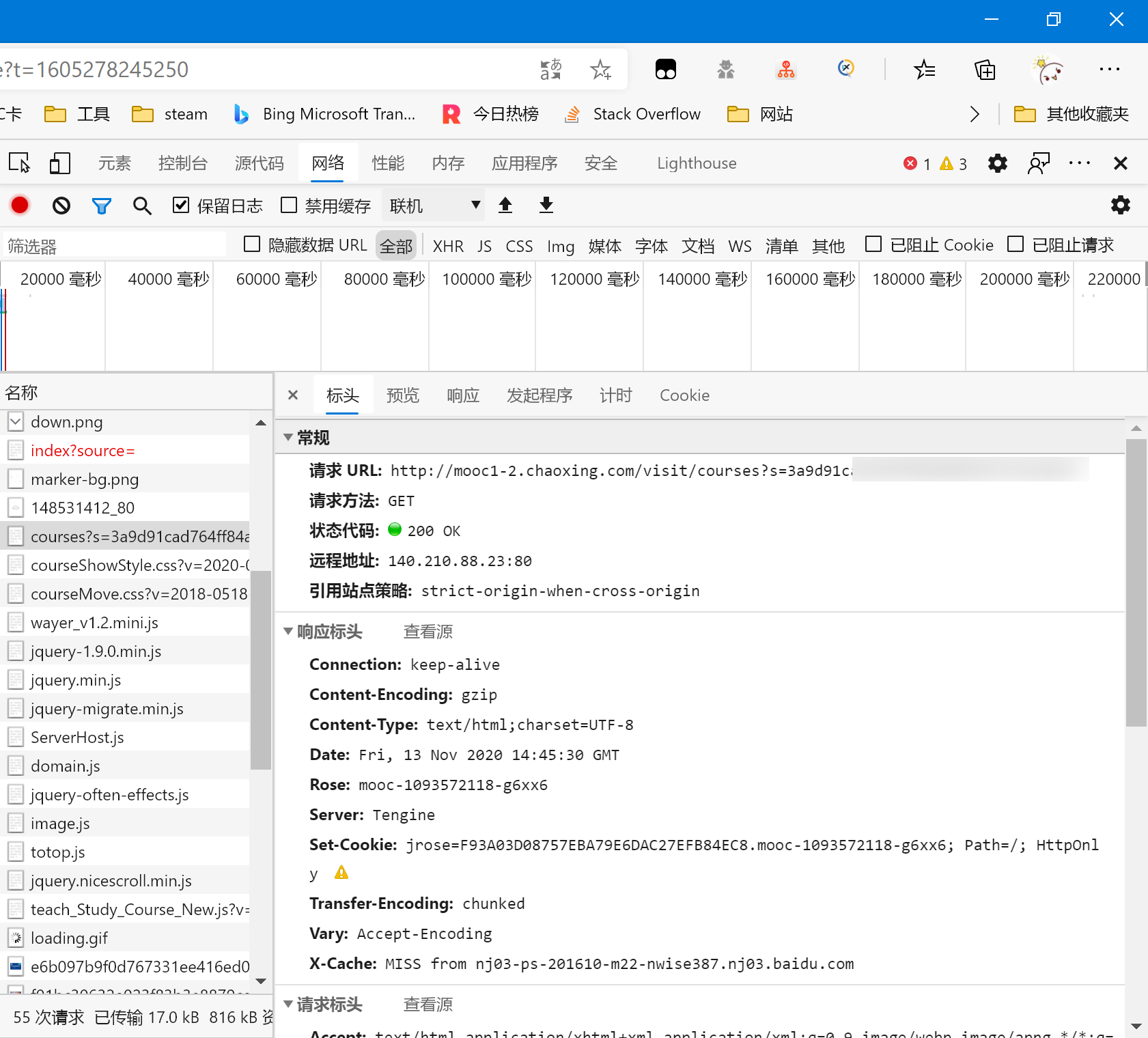
这个s参数肯定不会无故出现,所以我们往前寻找有没有前面就给出了这个地址的,我们从最前面找,看看最初的那个空间地址包里面有没有这个地址。
然而正当我打算尝试时,我发现把s参数去掉了一样可以正常访问我们的课程数据http://mooc1-2.chaoxing.com/visit/courses
那么为了尽可能简化,我们还是能偷懒就偷懒。
然后我们跳到代码阶段,先试试前面的cookie能否正常使用,并且读取到这个课程网页的信息。
点我跳转
解析课程信息
因为课程数据已经在http://mooc1-2.chaoxing.com/visit/courses 这个包里给出了,但它又不是一个json,所以我们把它作为一个单独的网页来进行结构分析。
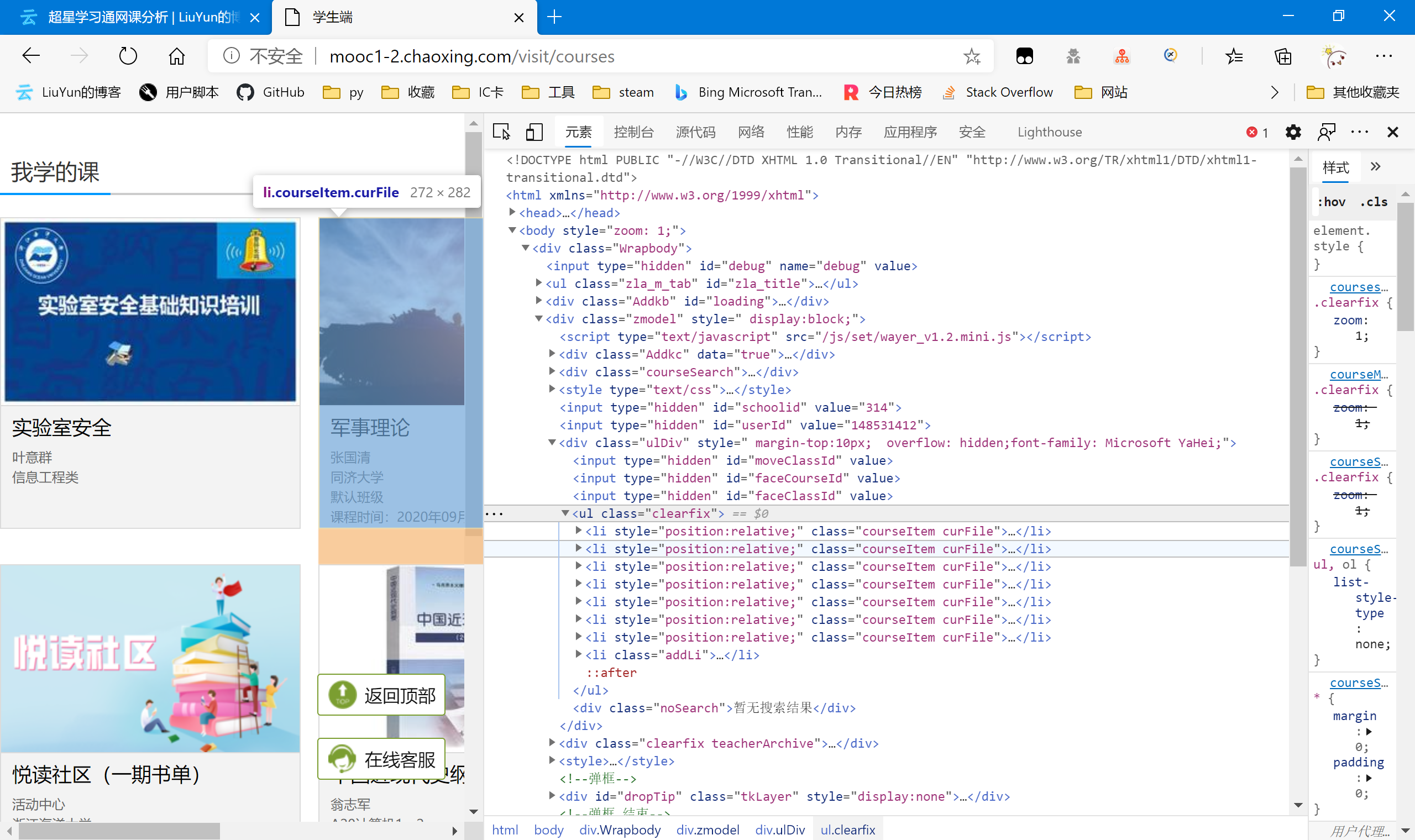
可以看到课程是一个ul结构下的多个li构成的。我们需要的里面每个课程的courseId classId与对应跳转的url(因为url里包含了courseid与classid,所以我们可以选择一是通过xpath先储存并关联url与对应的课程id;亦或是只获取url,后面再从url里读取参数courseid,classid等)。选中我们要的元素,右键复制xpath。
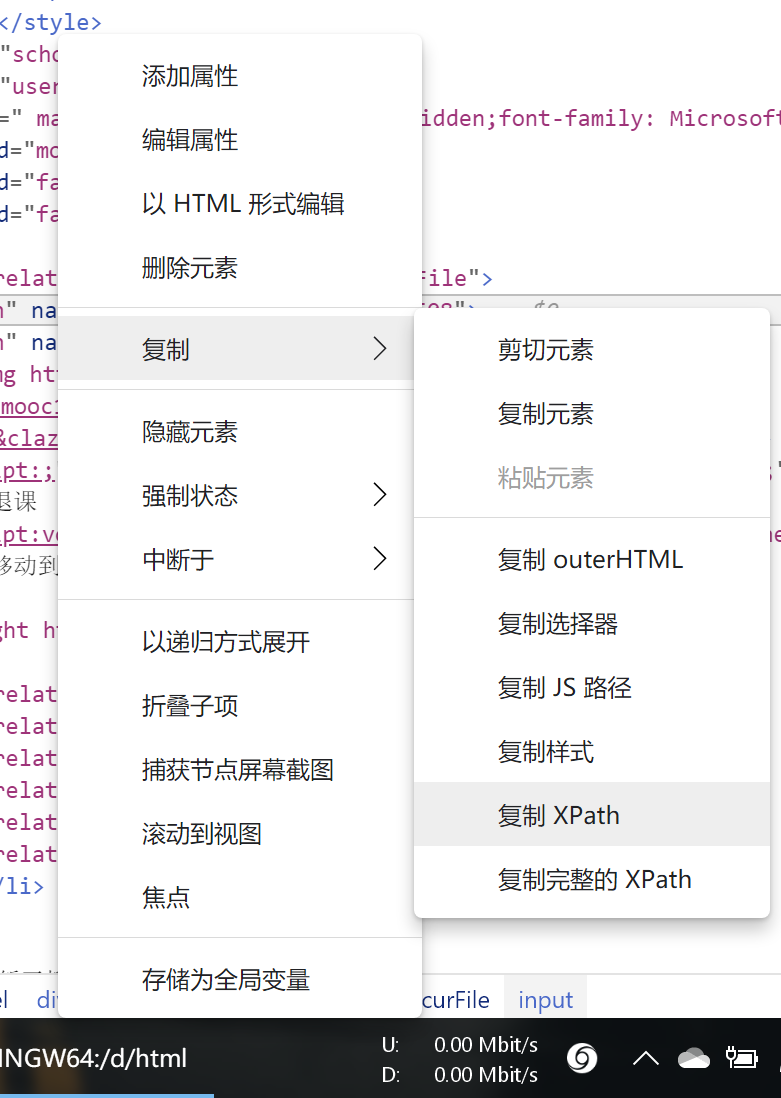
这里我选择了第二种方案,只获取url,courseid从url中读取。我们继续跳到代码步骤。
点我跳转
代码撰写
尝试cookie与读取课程信息
将登录获取到的cookie合并成cookiestr后传入获取课程信息的函数
| def get_course(cookie:str):
course_headers={
'Cookie':cookie,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
course_rsp=requests.get(url="http://mooc1-2.chaoxing.com/visit/courses",headers=course_headers)
print(course_rsp.text)
|
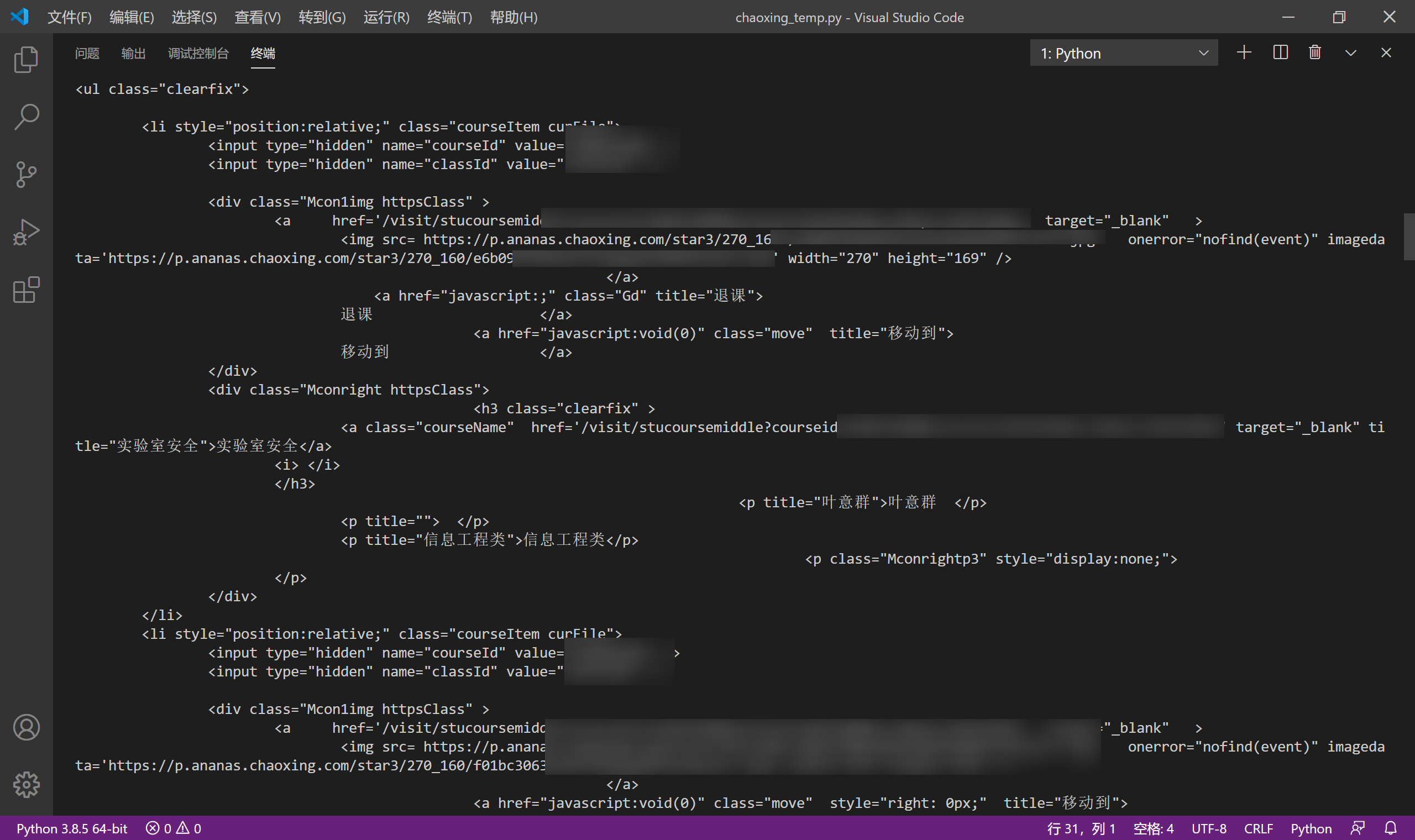
可以看到,成功获取到了课程信息,同时也印证了我们前面登录函数的可行性。
之后回到网页,我们继续分析网页结构,使python可以解析我们的所有课程及相关信息。
点我跳转
课程xpath书写与重定向问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def get_course(cookie:str):
course_headers={
'Cookie':cookie,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
course_rsp=requests.get(url="http://mooc1-2.chaoxing.com/visit/courses",headers=course_headers)
if course_rsp.status_code==200:
from lxml import etree
class_HTML=etree.HTML(course_rsp.text)
print("处理成功,您当前已开启的课程如下:\n")
i=0
global course_dict
course_dict={}
for class_item in class_HTML.xpath("/html/body/div/div[2]/div[3]/ul/li[@class='courseItem curFile']"):
try:
class_item_name=class_item.xpath("./div[2]/h3/a/@title")[0]
i+=1
print(class_item_name)
course_dict[i]=[class_item_name,"https://mooc1-2.chaoxing.com{}".format(class_item.xpath("./div[1]/a[1]/@href")[0])]
except:
pass
print("———————————————————————————————————")
else:
print("error:课程处理失败")
|

课程读取成功了,课程的url与name也作为list被我们关联储存到了course_dict这个dict中(为了使序号与课程进行关联,并且保持有序性)
课程获取完后我们就可以开始针对单个课程,读取里面的待完成视频任务添加到程序任务里。然而,仔细观察我们从html里获取到的url

与我们手动访问课程获取的url

发现两者并不相同,我们尝试访问html里的url,然后抓包看发生了什么
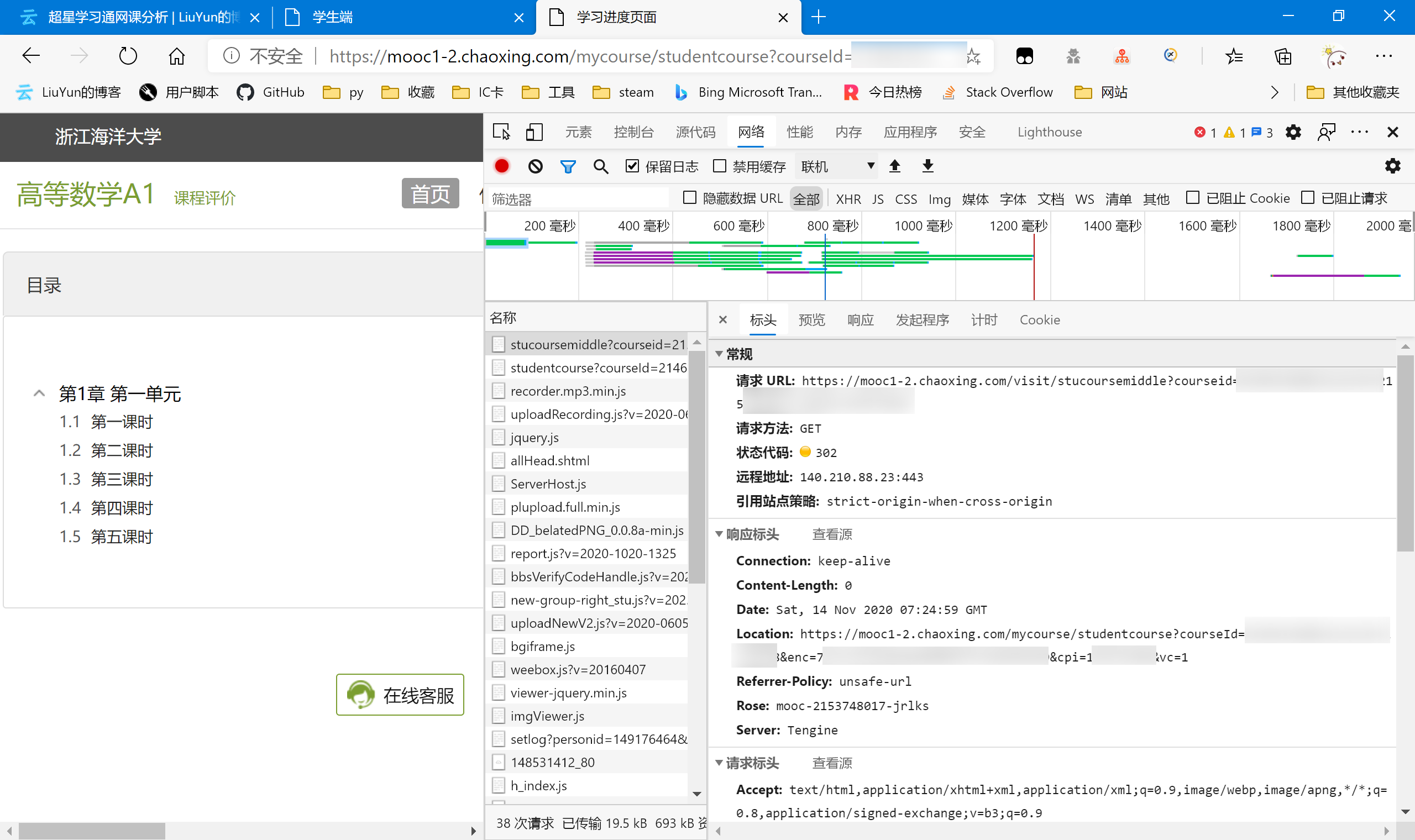
不出所料,果然url发生了302重定向。
本来requests库是会识别302并自动跟随跳转的,但不知道为什么我这里出现了错误,并未跟随跳转,甚至让我一度怀疑问题出在了cookie上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def deal_course(url:str):
course_302_url=url
course_headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection':'keep-alive',
'Cookie':cookieStr,
'Host':'mooc1-2.chaoxing.com',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'none',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
course_302_rsp=requests.get(url=course_302_url,headers=course_headers,allow_redirects=False)
new_url=course_302_rsp.headers['Location']
|
这样,只需要将html里获取到的url传入到这个函数里,new_url就是我们要的真正的课程地址了。
真正的课程地址获取完成了,接下来我们继续回到网络分析,分析单个课程中我们需要完成的任务。
课程任务
分析网页
任意进入到一个课程中,通过观察可以发现:白色无内容的——没有任务;橙色有数字的——数字代表该章节的任务数;绿色勾勾的——有任务但已完成了的。
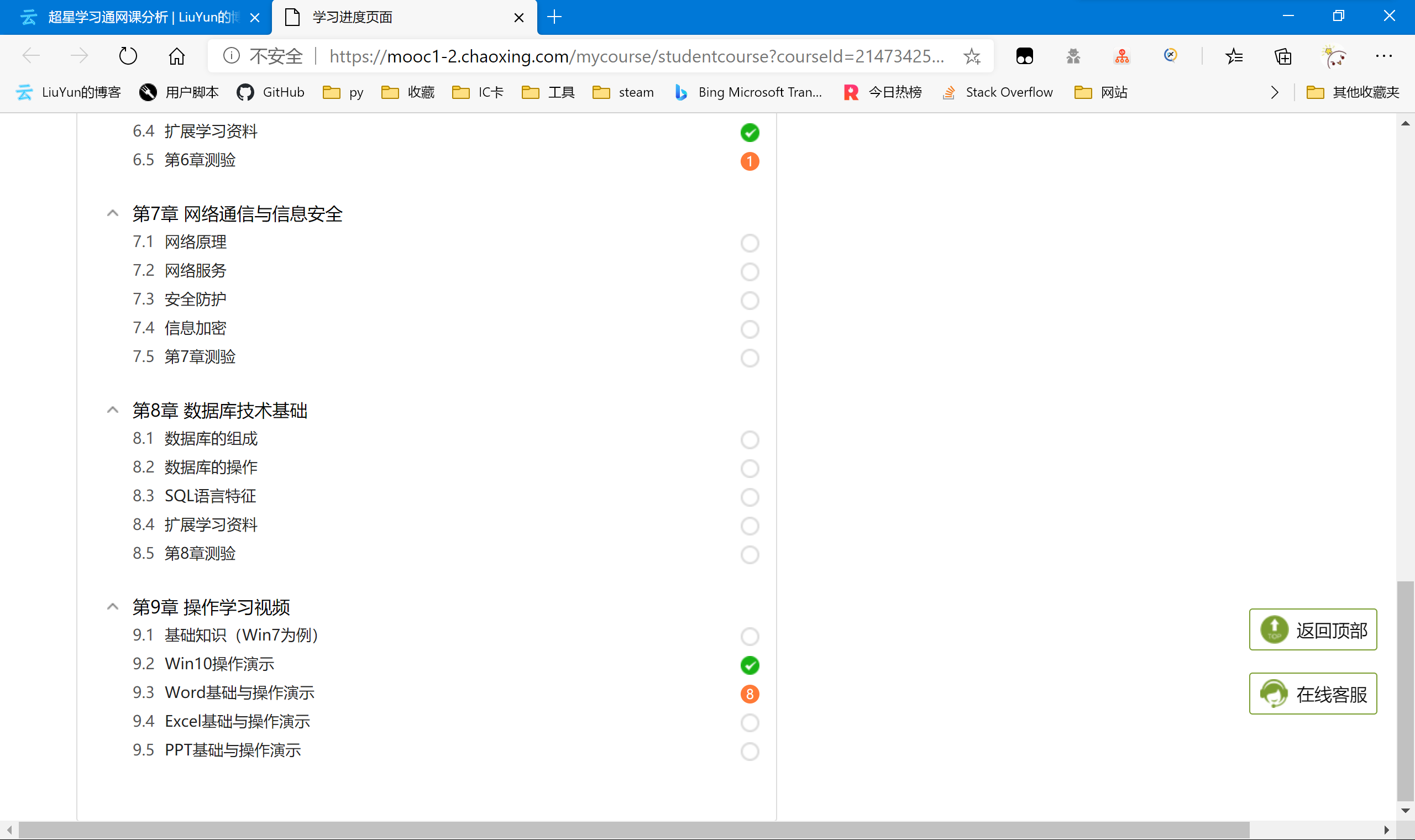
刷新一下,发现该课程地址就已经给出了相关的章节信息,即在服务端已经渲染好了再传输到用户端,并没有额外的json数据包。
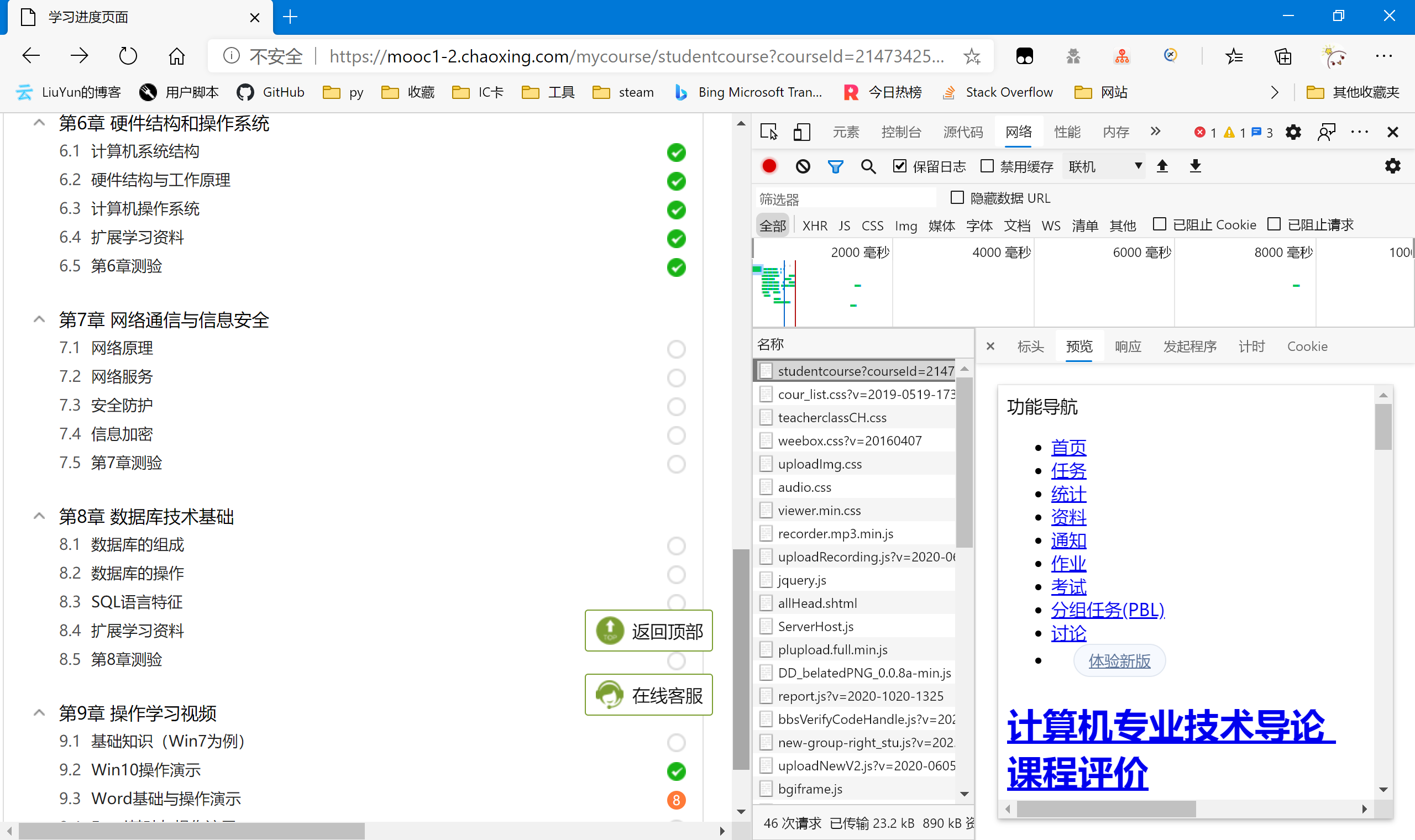
所以我们直接右键“检查”,查看网页元素。
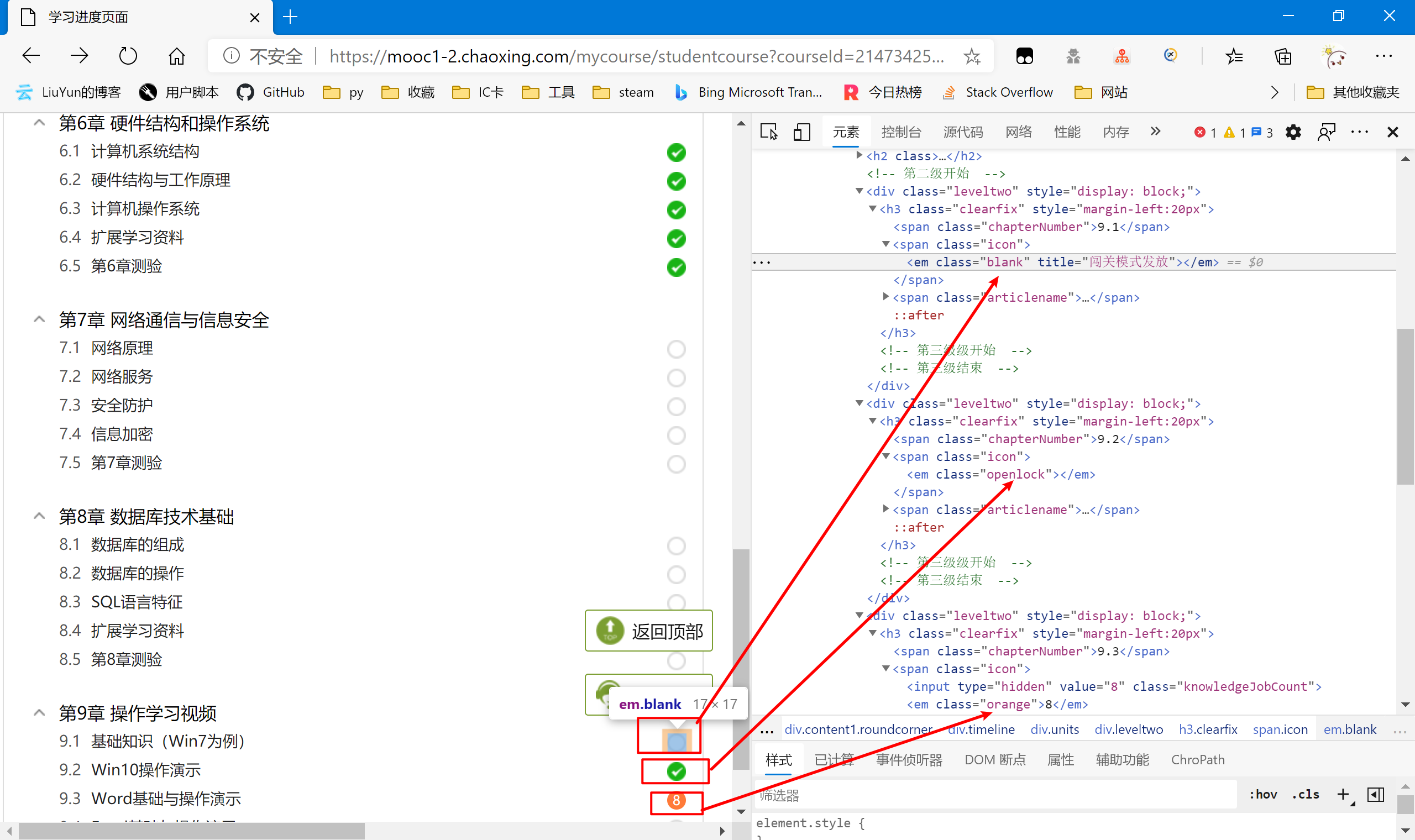
找规律可以发现,正常的没有课程任务的,em元素的class是“blank”,如果有任务但已完成则是“openlock”,如果有任务但未完成则class为“orange”,且其text为任务数。
知道了这个,我们就好写了,只需要判断em元素class属性是orange的,并把它对应的url写入我们的任务列表里。所以接下来回到代码环节
代码编写
章节信息判断与未完成任务读取
通过上面的分析,以及课程信息url的获取,将其传入的requests,获取源代码后即可进行判断处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| def add_misson(url:str):
course_headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection':'keep-alive',
'Cookie':cookieStr,
'Host':'mooc1-2.chaoxing.com',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'none',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
course_rsp=requests.get(url=url,headers=course_headers)
course_HTML=etree.HTML(course_rsp.text)
chapter_mission=[]
try:
for course_unit in course_HTML.xpath("/html/body/div[5]/div[1]/div[2]/div[3]/div"):
print(course_unit.xpath("./h2/a/@title")[0])
for chapter_item in course_unit.xpath("./div"):
chapter_status=chapter_item.xpath("./h3/span[@class='icon']/em/@class")[0]
if chapter_status == "orange":
print("----",chapter_item.xpath("./h3/span[@class='articlename']/a/@title")[0]," ",chapter_item.xpath("./h3/span[@class='icon']/em/text()")[0])
chapter_mission.append("https://mooc1-2.chaoxing.com{}".format(chapter_item.xpath("./h3/span[@class='articlename']/a/@href")[0]))
else:
print("----",chapter_item.xpath("./h3/span[@class='articlename']/a/@title")[0]," ",chapter_item.xpath("./h3/span[@class='icon']/em/@class")[0])
except:
pass
print("课程读取完成,共有%d个章节可一键完成"%len(chapter_mission))
|
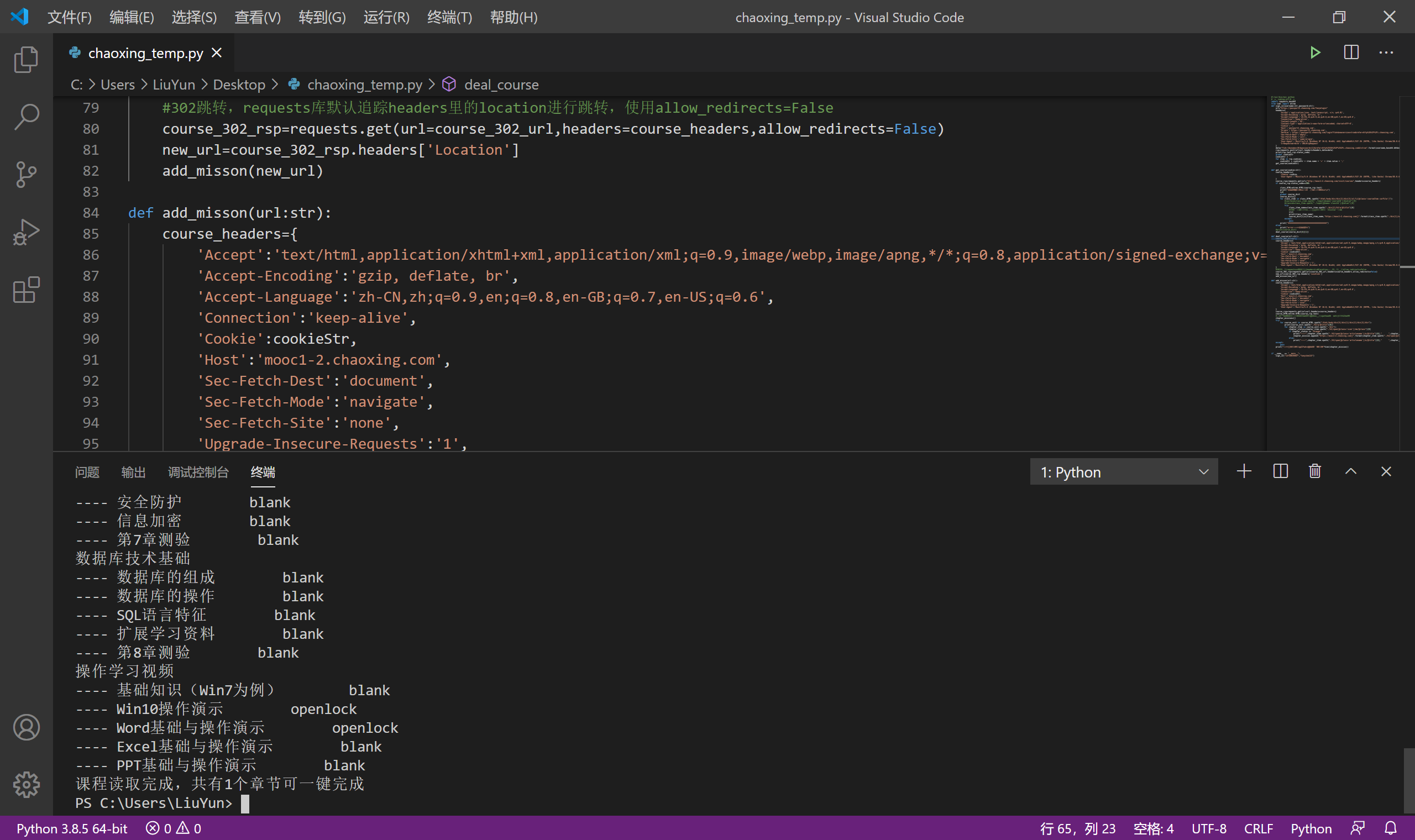
视频任务点
因为要实现的是一键刷课程视频,所以接下来我们要读取的是章节任务里面的视频任务点。
网页分析
还是老样子,先抓一下包。
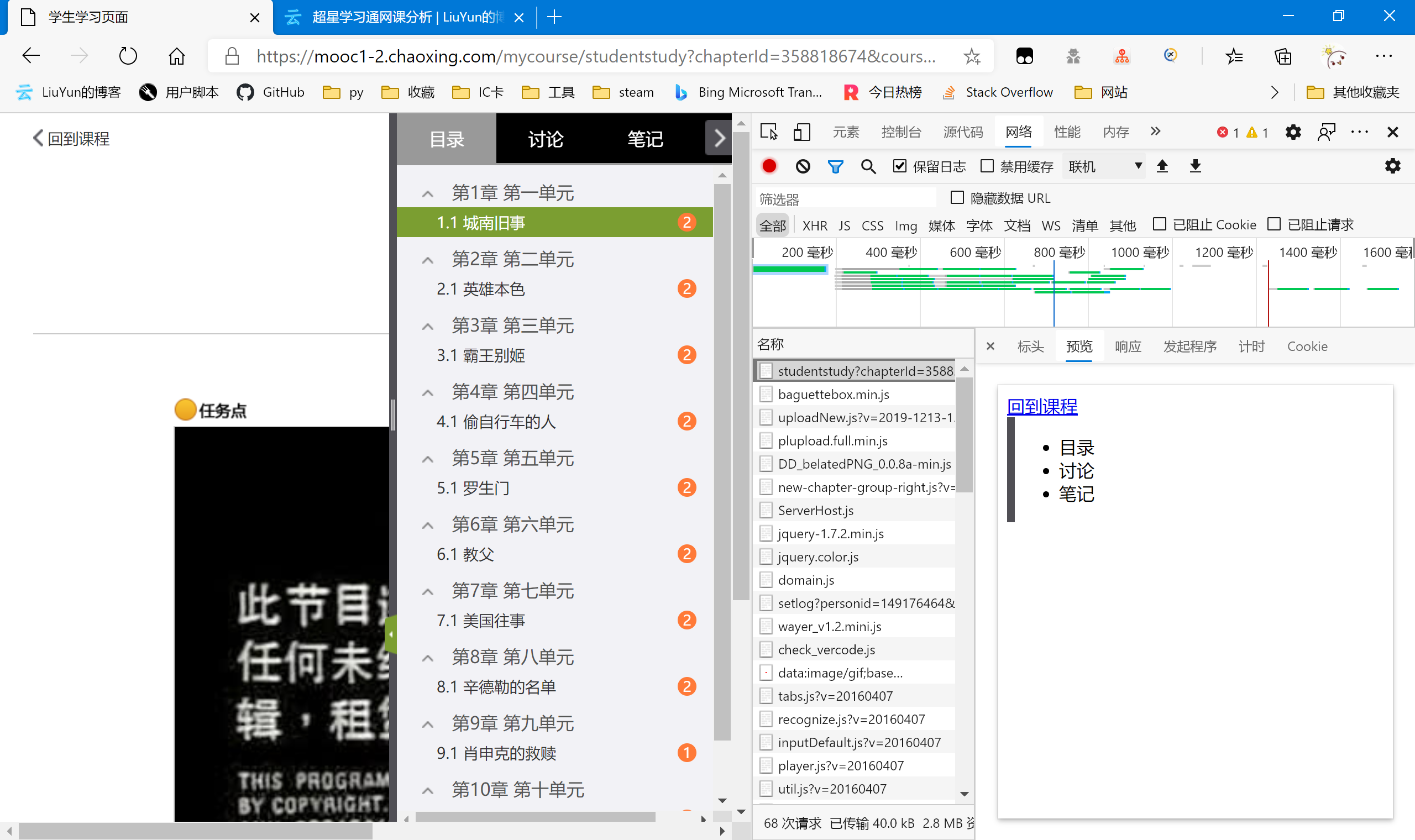
可以从预览里看出,章节网页似乎并没有完全渲染完成后再传输给我们。通过查看响应里面的代码,我们也验证了猜想,并未找到有关的视频数据。所以我们尝试往下寻找包含视频信息的json包或者html网页。
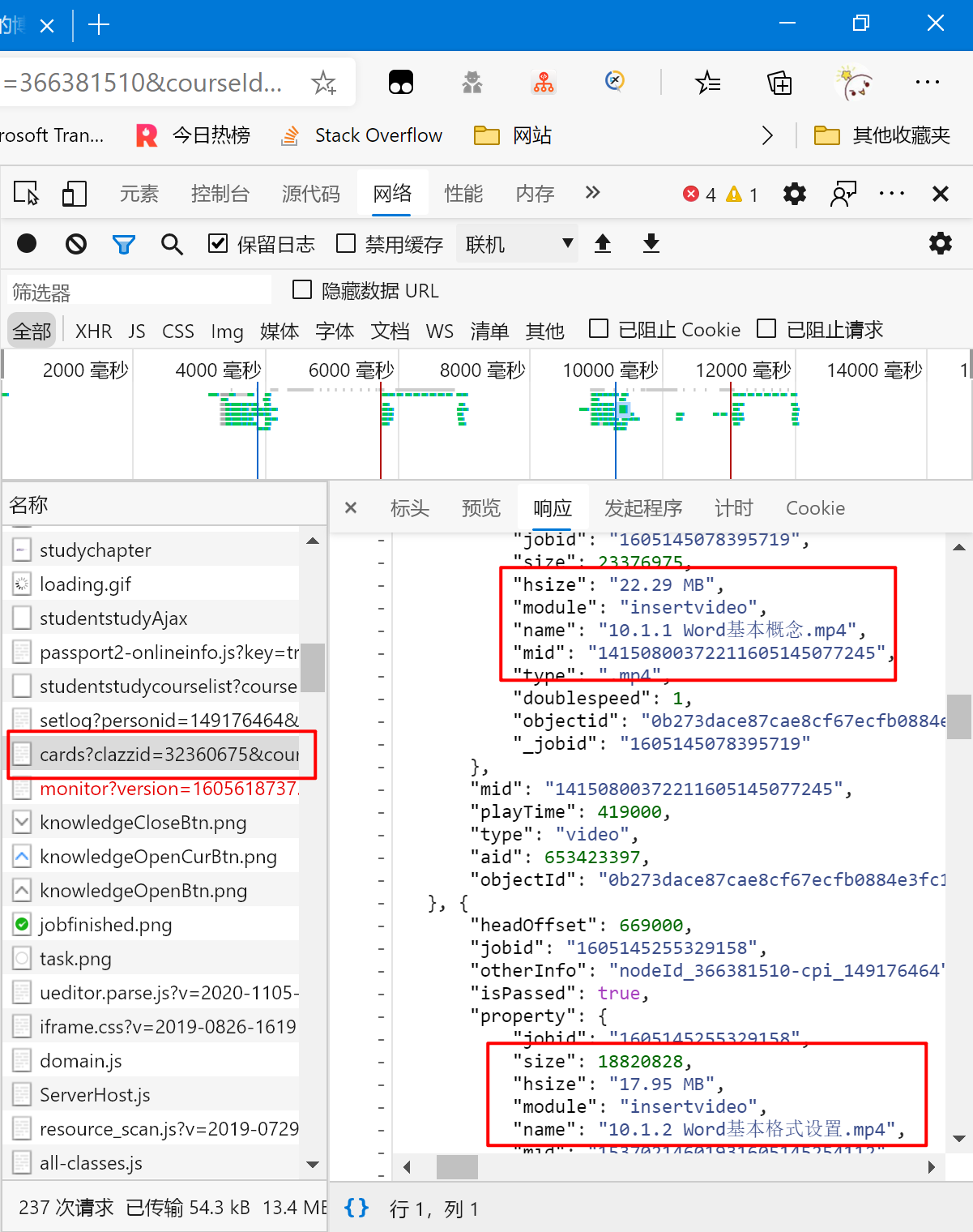
最后,在这个“/knowledge/cards”里的包里找到了我们要的数据,可惜它也不是json,而是一个html,里面有js代码。所以我们还得自己提取代码,并转化成python可识别的内容。这边的分析还是比较麻烦的,但并不算难,只能说不熟练的话需要多试试。这个就请自己尝试看看吧,这边就不给出具体分析过程了(因为自己也想不起来了,也不想再分析一遍,懒)。不过如果实在有问题的话也可以联系我,和我交流交流。那我们就直接进入代码环节然后给出代码。
我们顺便分析一下这些视频数据代表的内容。
“isPassed”是任务点是否已完成,true为已完成,false为未完成,所以我们可以通过判断它的属性来直接判断是否需要对该视频进行处理。
“type”: “video”是类型为视频,也是我们判断是否要添加到任务列表的一个条件(因为我们要实现的只有刷超星视频),其他还有可能出现ppt这种。
其他其实通过名字也都能知道是什么,主要还是要看后面我们需要用到什么属性。
代码编写
为了把js代码提取出来并变成python中的dict或list,我这里用到了正则表达式,取出我们要的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def deal_misson(missons:list,class_cpi:str):
for chapter_mission_item in missons:
result = parse.urlparse(chapter_mission_item)
chapter_data=parse.parse_qs(result.query)
print(chapter_data)
medias_url="https://mooc1-2.chaoxing.com/knowledge/cards?clazzid={0}&courseid={1}&knowledgeid={2}&num=0&ut=s&cpi={3}&v=20160407-1".format(chapter_data.get('clazzid')[0],chapter_data.get('courseId')[0],chapter_data.get('chapterId')[0],class_cpi)
class_headers={
'Cookie':cookieStr,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
medias_rsp=requests.get(url=medias_url,headers=class_headers)
medias_HTML=etree.HTML(medias_rsp.text)
medias_text=medias_HTML.xpath("//script[1]/text()")[0]
import re,json
pattern = re.compile(r'attachments":([\s\S]*),"defaults"')
re_result=re.findall(pattern,medias_text)[0]
reportUrl=re.findall(r'reportUrl":([\s\S]*),"chapterCapture"',medias_text)[0]
reportUrl=reportUrl.replace("\"","")
result_json=json.loads(re_result)
|
这里传入的missons是每个章节的链接构成的一个list,至于class_cpi是课程的cpi信息,每个课程中的所有章节中的所有视频都共用这个cpi属性,而这个是后面完成视频要用到的,针对我们现在判断视频任务并用不到。result_json即是我们从网页代码中提取出的json。
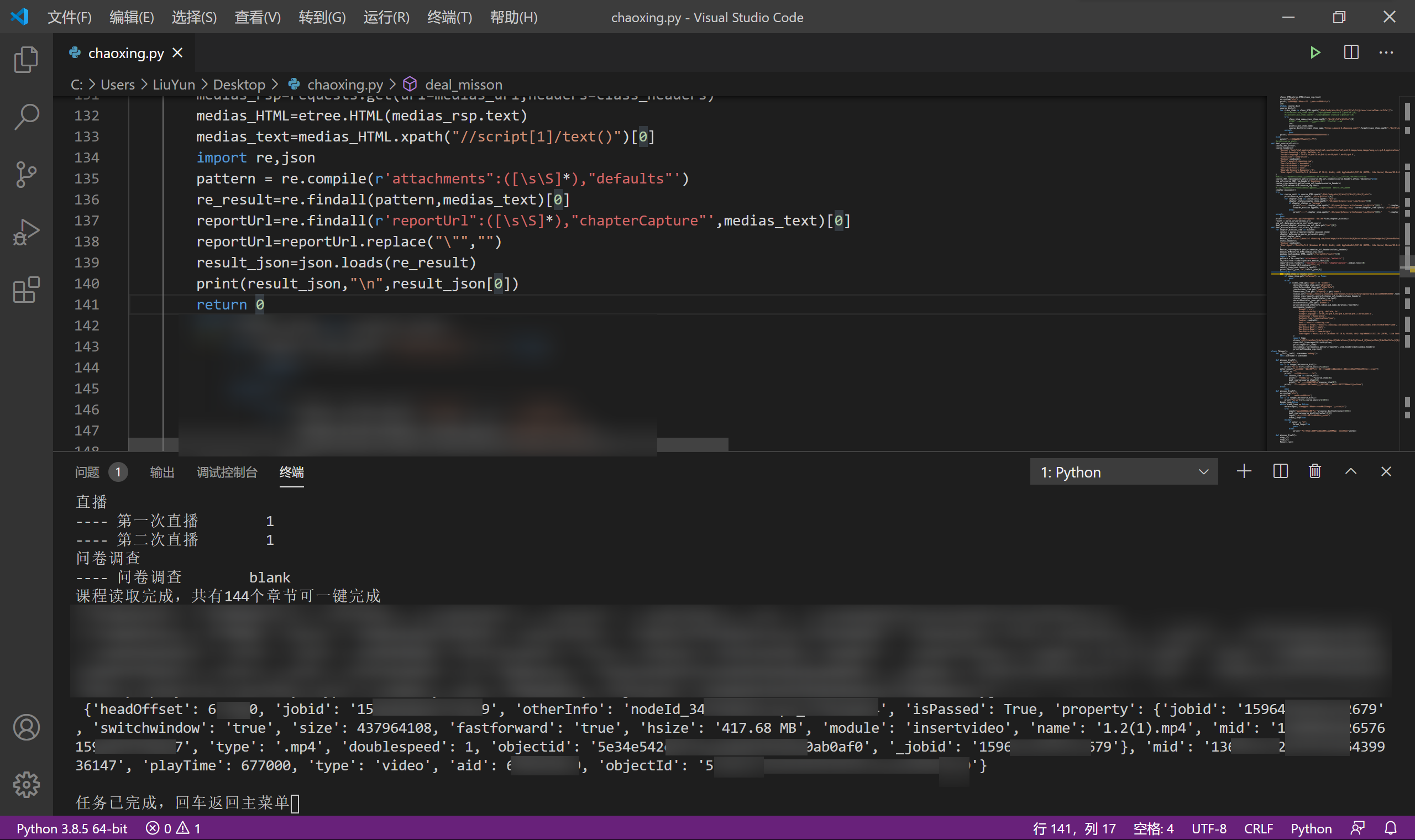
可以看到,调试成功了,而且是很完美的json格式,loads我们可以用list的操作方式轻松的调用其中的数据信息。
章节中的视频信息我们也处理完成了,到此我们的准备工作已经都完成了。账号登录——判断课程信息——判断课程中的章节任务——判断章节里面的视频任务,最后一步就是完成章节里的视频任务了,也是我们最后的大头。
任务完成解析
抓包分析
打开“开发者选项”,进行抓包,然后播放视频。出现了两个包
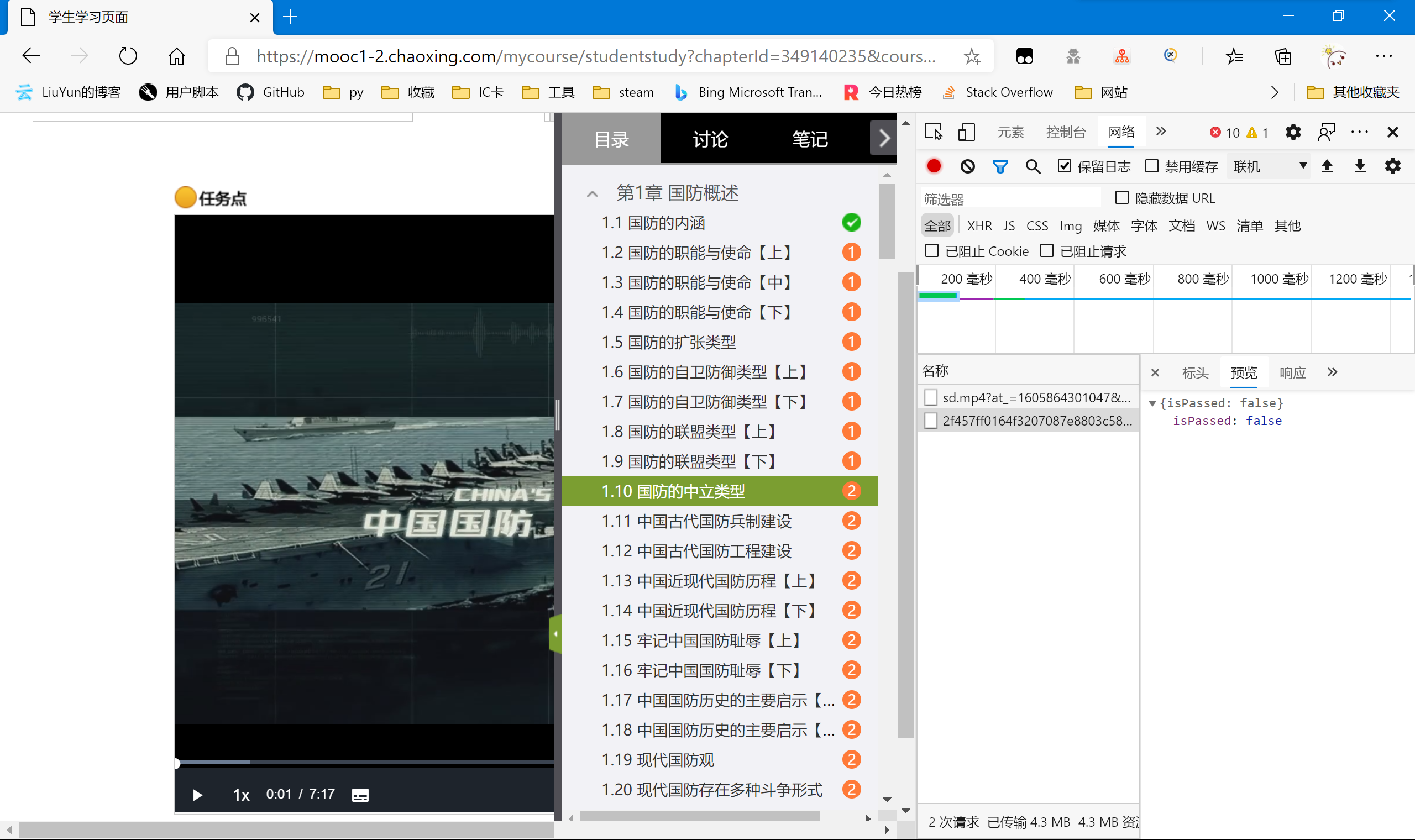
第一个是视频的包,用于向服务器请求视频数据,从其中的type,以及一些其他的headers都能看出来。
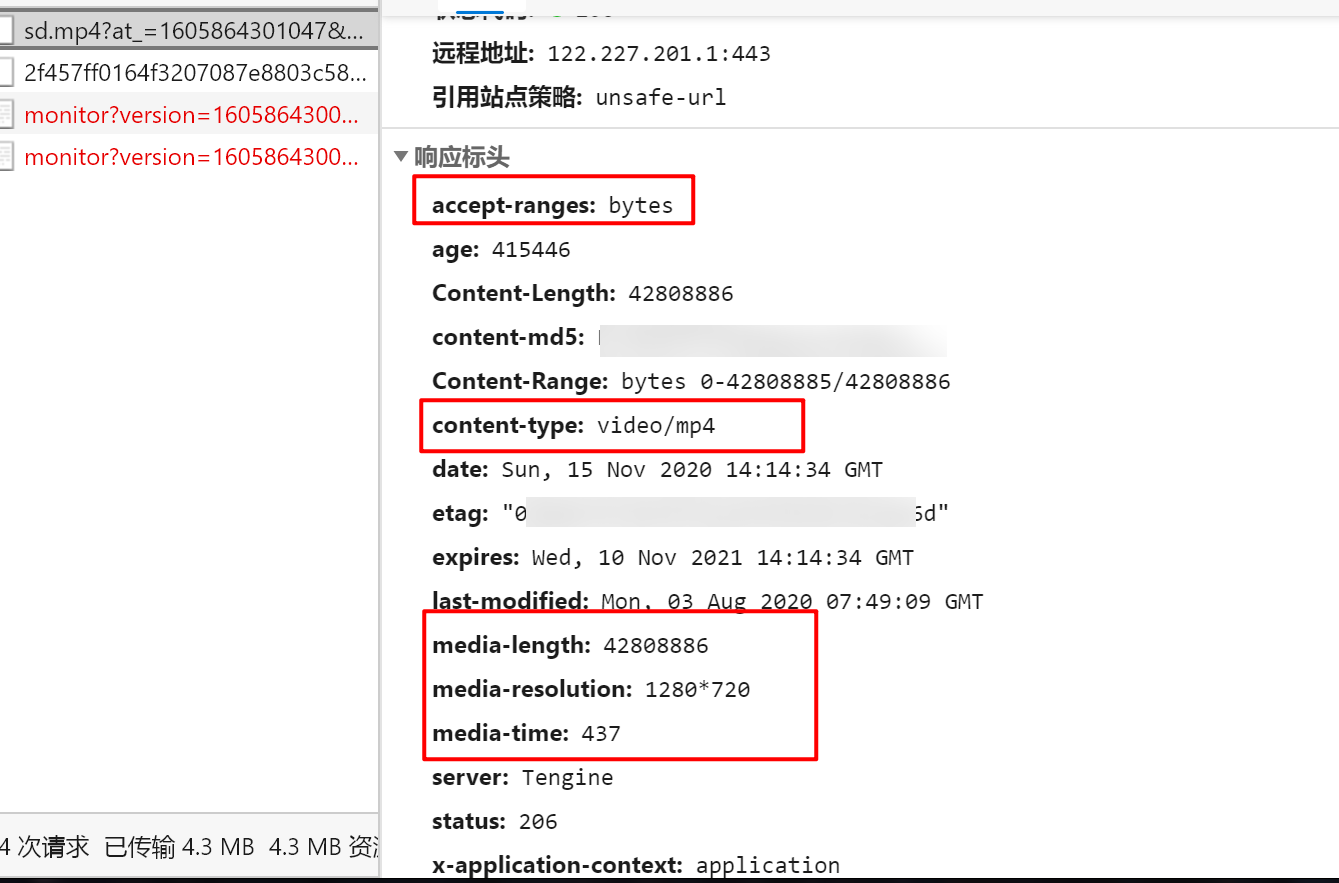
第二个包,就是我们要的用来完成任务的包了。它传输的是你观看的数据,返回的isPassed来说明你的任务是否完成了。因为我们只是播放了一下,所以任务当然没能完成,所以返回的数据是{“isPassed”:false}。
然后我们等视频放完,即将任务点完成,看它会发送什么包,与前面这个包有什么区别。
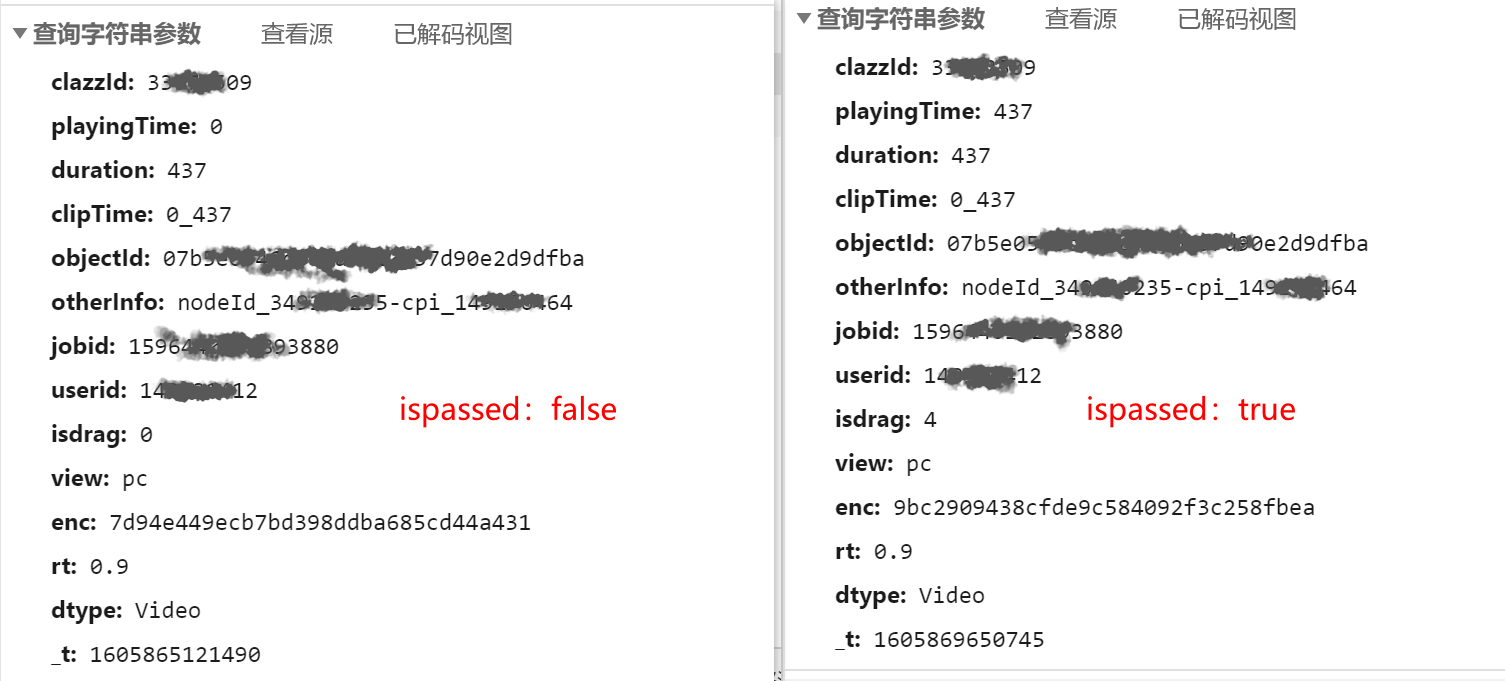
可以看出主要区别就在这个playingTime,翻译下来也很好理解,应该就是我们播放了的时间。只要这个时间等于视频的总长度,那么就算我们就完成了。接下来我们分析下提交的整个表单。
| key |
含义 |
来源 |
| clazzId |
章节ID |
单个章节的url里 |
| playingTime |
视频播放的时间 |
自己修改,通过读取视频的长度信息 |
| duration |
时间 |
与playingtime同步,都为视频的总时长 |
| clipTime |
起止时间? |
“0_”加上总时长,即与前面两个参数一样,但在前方加上”0_” |
| objectId |
视频的“objectId”属性 |
由视频任务点中的所有视频信息“result_json” 里面的单个视频数据中给出。 |
| otherInfo |
视频的“otherInfo”属性 |
由视频任务点中的所有视频信息“result_json” 里面的单个视频数据中给出。 |
| jobid |
视频的“jobid”属性 |
由视频任务点中的所有视频信息“result_json” 里面的单个视频数据中给出。 |
| userid |
用户id信息 |
由登录时获取的cookie里获取 |
| isdrag |
视频状态信息,0:默认;3:播放;2:暂停;4:视频结束。 |
我们要用的是状态4,将其作为常量 |
| view |
终端情况? |
值为”pc”,我们将其作为常量不修改它 |
| enc |
是其他表单所有数据经过算法计算后得出的数据校验码 |
全篇的最难点,见后面分析 |
| rt |
不清楚 |
将值0.9作为常量 |
| dtype |
任务类型 |
因为我们要实现的功能仅有视频,所以将值Video作为常量 |
| _t |
时间戳 |
可以添加实时时间戳,也可以沿用,服务端不会进行校验 |
以下我将给出以上部分参数含义及来源的代码依据。
clipTime
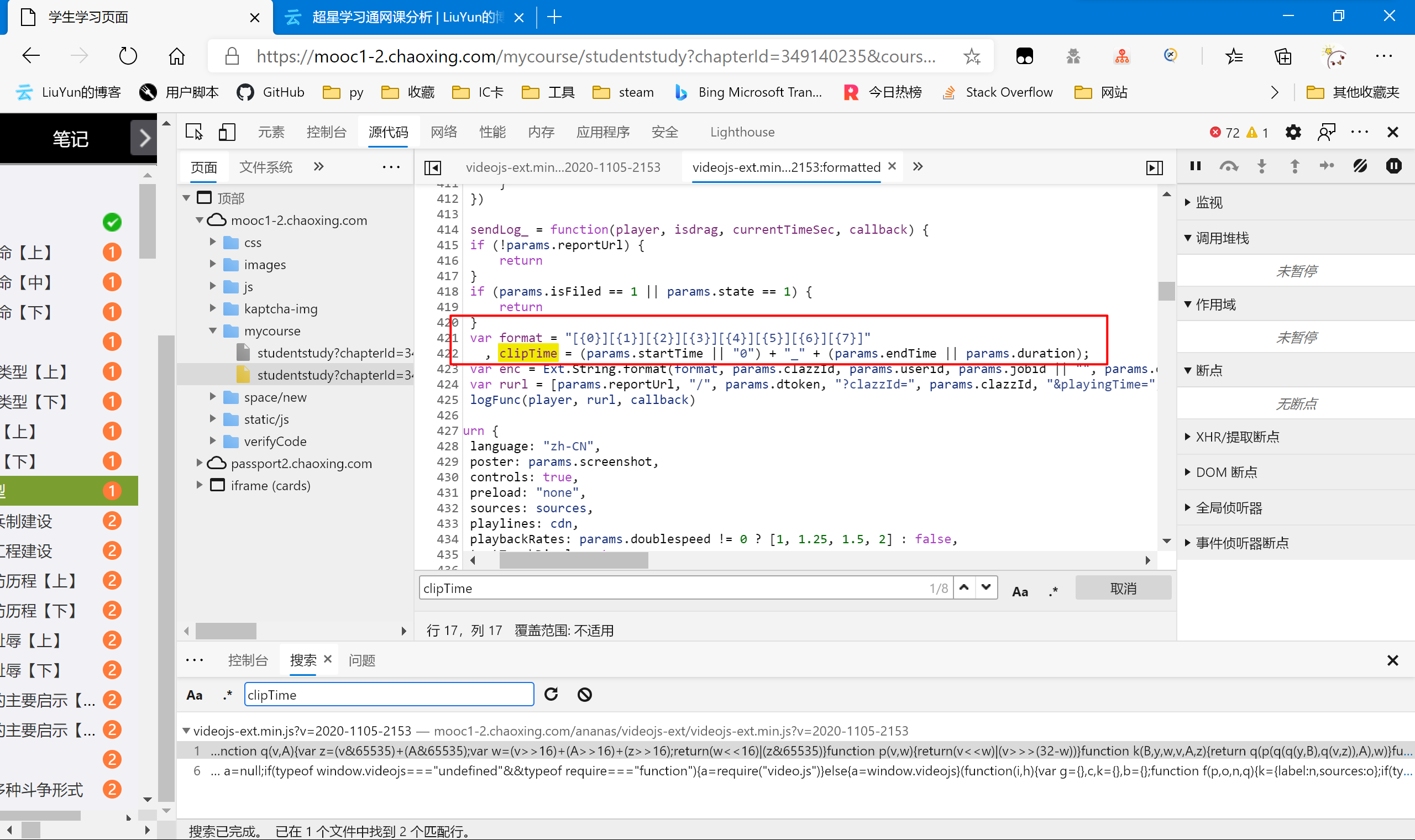
| clipTime = (params.startTime || "0") + "_" + (params.endTime || params.duration);
|
以上是源代码,不难看懂,clipTime的值是 起始时间或”0” + “_” + 终止时间或duration 。
isdrag
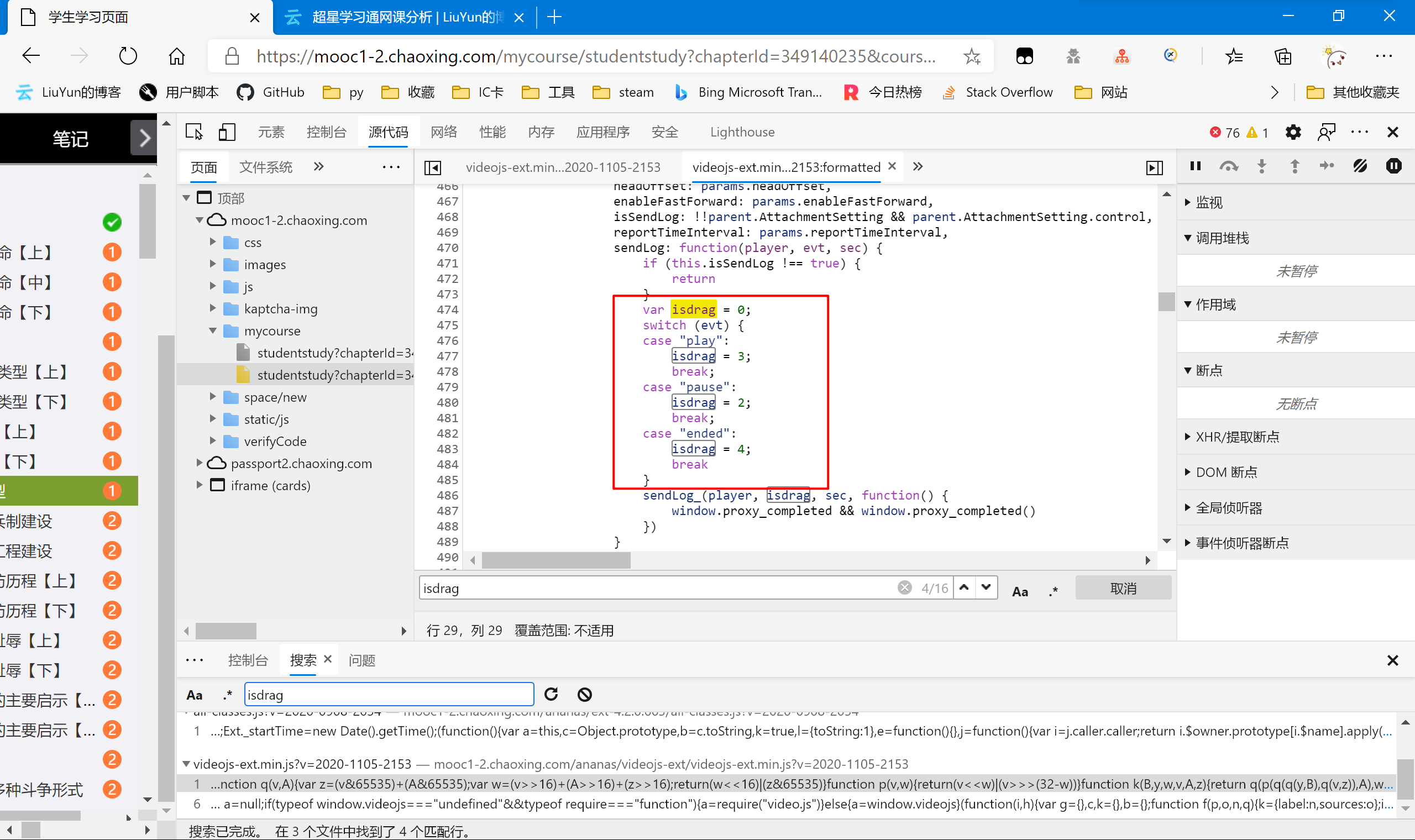
| var isdrag = 0;
switch (evt) {
case "play":
isdrag = 3;
break;
case "pause":
isdrag = 2;
break;
case "ended":
isdrag = 4;
break
}
|
因为我们要完成任务,自然是视频播放完结束后发送的包,所以为ended,所以我们用“4”作为常量值。
rt
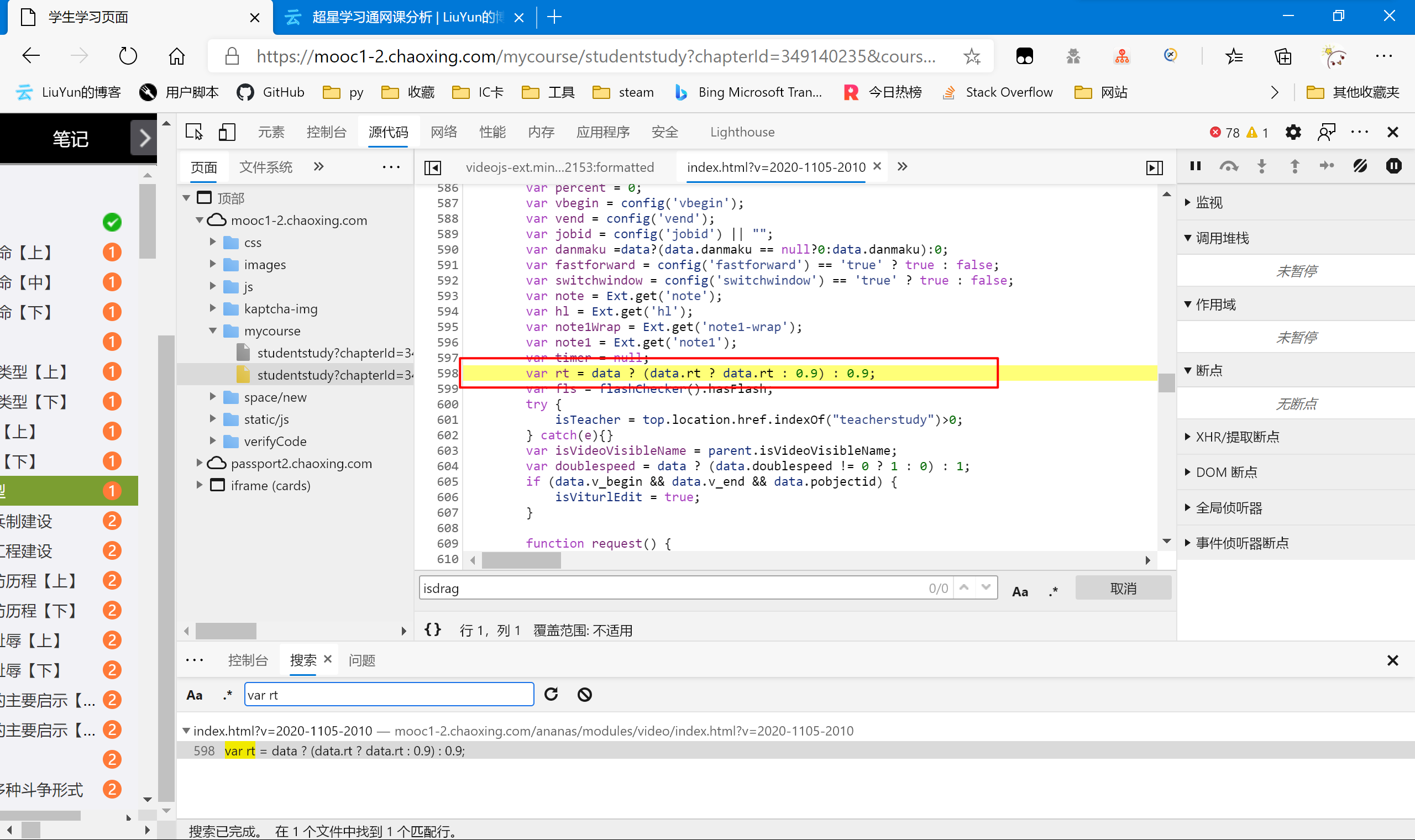
| var rt = data ? (data.rt ? data.rt : 0.9) : 0.9;
|
没学过js的我也不太清楚这段话的具体作用,不过我们把“0.9”作为常量传输不会有任何异常。
这里有个小细节,就是当我们全站检索“rt”时因为字符数较少,会出现较多的结果(因为很多函数或变量里都会包含这两个字符,所以我们搜索 rt 的定义语句——“var rt”,即可减少结果。
enc
全文的最难点,以上所有数据的校验码。以下将给出我个人尝试破解的详细思路。
首先我选择全站检索enc,尝试找到它的由来。
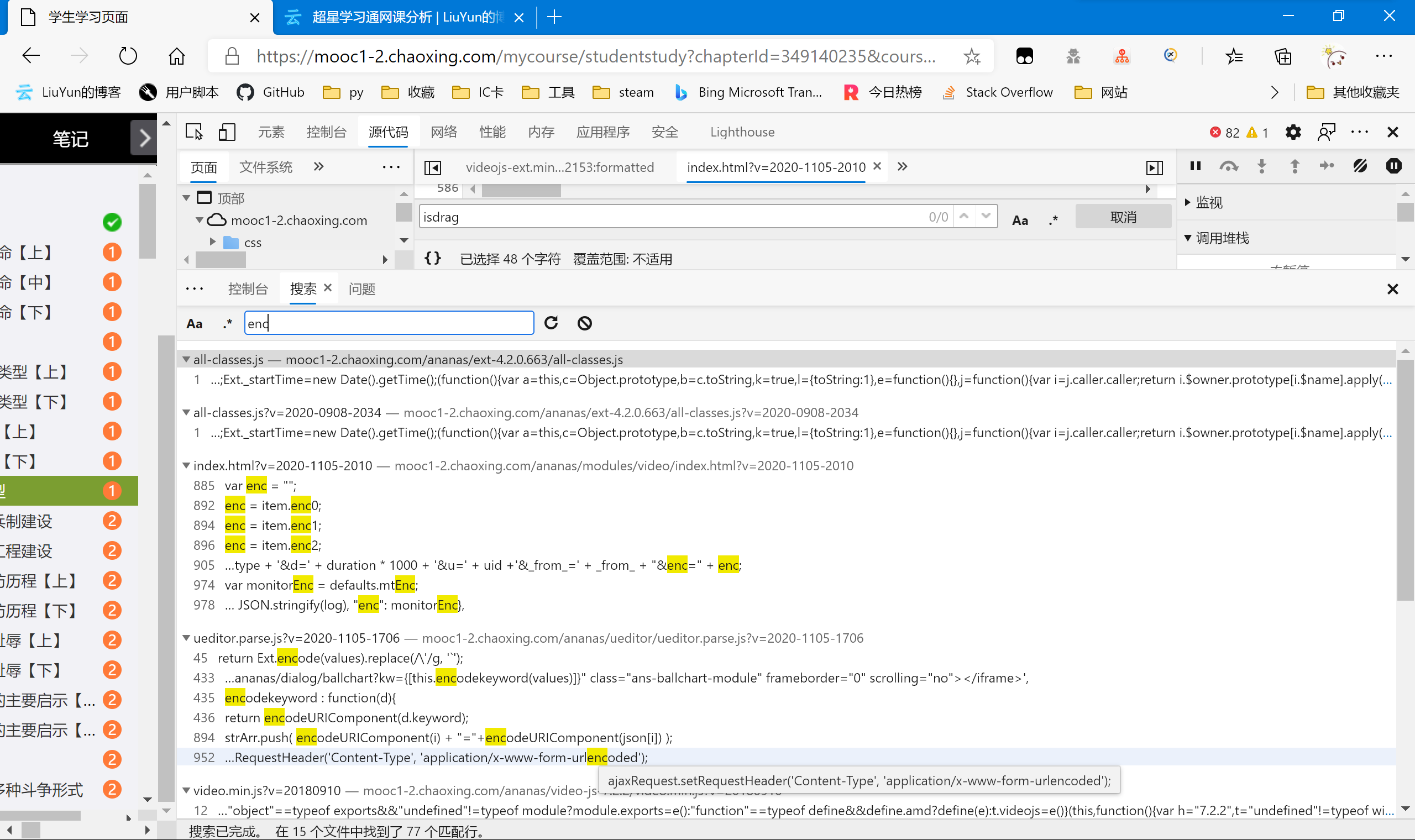
可以看到,出现了很多的数据(15个文件共77行匹配),所以为了缩小范围,我尝试跟上面的rt一样操作,查询enc的赋值语句。
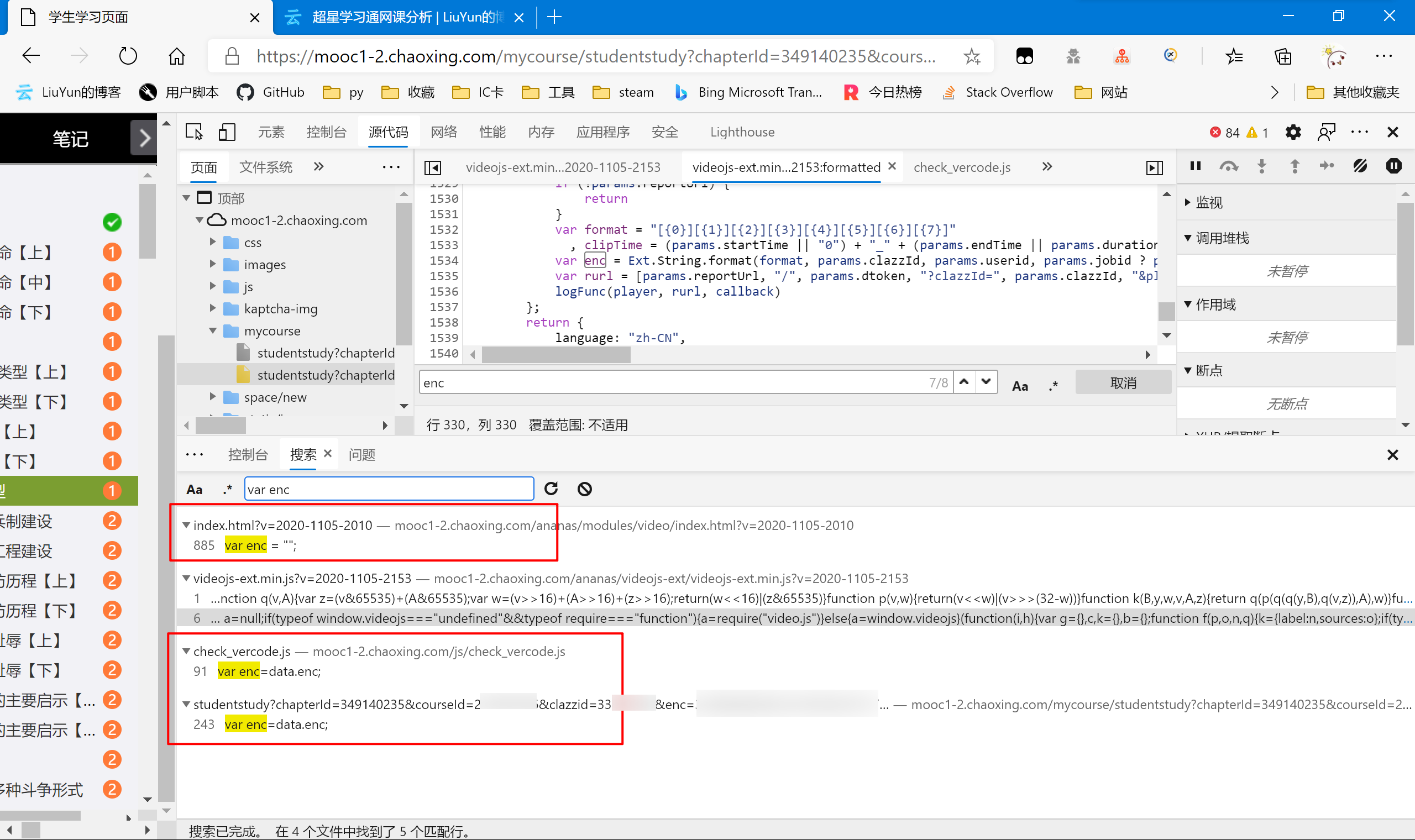
很有效果,结果只有4个文件5行匹配。而如图红色圈起来的代码,虽然都对enc进行了赋值,但都不是我们要的语句。我们一个个手动排除,最后我锁定了 https://mooc1-2.chaoxing.com/ananas/videojs-ext/videojs-ext.min.js 这个文件,细心的朋友可能已经发现了,就是我们刚才找clipTime的那个地方。
| var sendLog_ = function(player, isdrag, currentTimeSec, callback) {
if (!params.reportUrl) {
return
}
if (params.isFiled == 1 || params.state == 1) {
return
}
var format = "[{0}][{1}][{2}][{3}][{4}][{5}][{6}][{7}]"
, clipTime = (params.startTime || "0") + "_" + (params.endTime || params.duration);
var enc = Ext.String.format(format, params.clazzId, params.userid, params.jobid || "", params.objectId, currentTimeSec * 1000, "d_yHJ!$pdA~5", params.duration * 1000, clipTime);
var rurl = [params.reportUrl, "/", params.dtoken, "?clazzId=", params.clazzId, "&playingTime=", currentTimeSec, "&duration=", params.duration, "&clipTime=", clipTime, "&objectId=", params.objectId, "&otherInfo=", params.otherInfo, "&jobid=", params.jobid, "&userid=", params.userid, "&isdrag=", isdrag, "&view=pc", "&enc=", md5(enc), "&rt=", params.rt, "&dtype=Video", "&_t=", new Date().getTime()].join("");
logFunc(player, rurl, callback)
};
|
把里面关于enc的代码提取出来
| var format = "[{0}][{1}][{2}][{3}][{4}][{5}][{6}][{7}]"
var enc = Ext.String.format(format, params.clazzId, params.userid, params.jobid || "", params.objectId, currentTimeSec * 1000, "d_yHJ!$pdA~5", params.duration * 1000, clipTime);
"&enc=", md5(enc)
|
大致意思就是令
enc=[clazzId][userid][jobid][objectId][currentTimeSec * 1000][“d_yHJ!$pdA~5”][duration * 1000][clipTime]
然后再将取enc的md5,作为表单的校验码。这里面的参数多是前面已经分析过了的,只是中间多了一个字符串常量 "d_yHJ!$pdA~5" 。还有一个可能不太清楚的就是currentTimeSec了。
我们设置断点,一边看看这个currentTimeSec到底是啥,顺便验证下我们前面的是否正确。
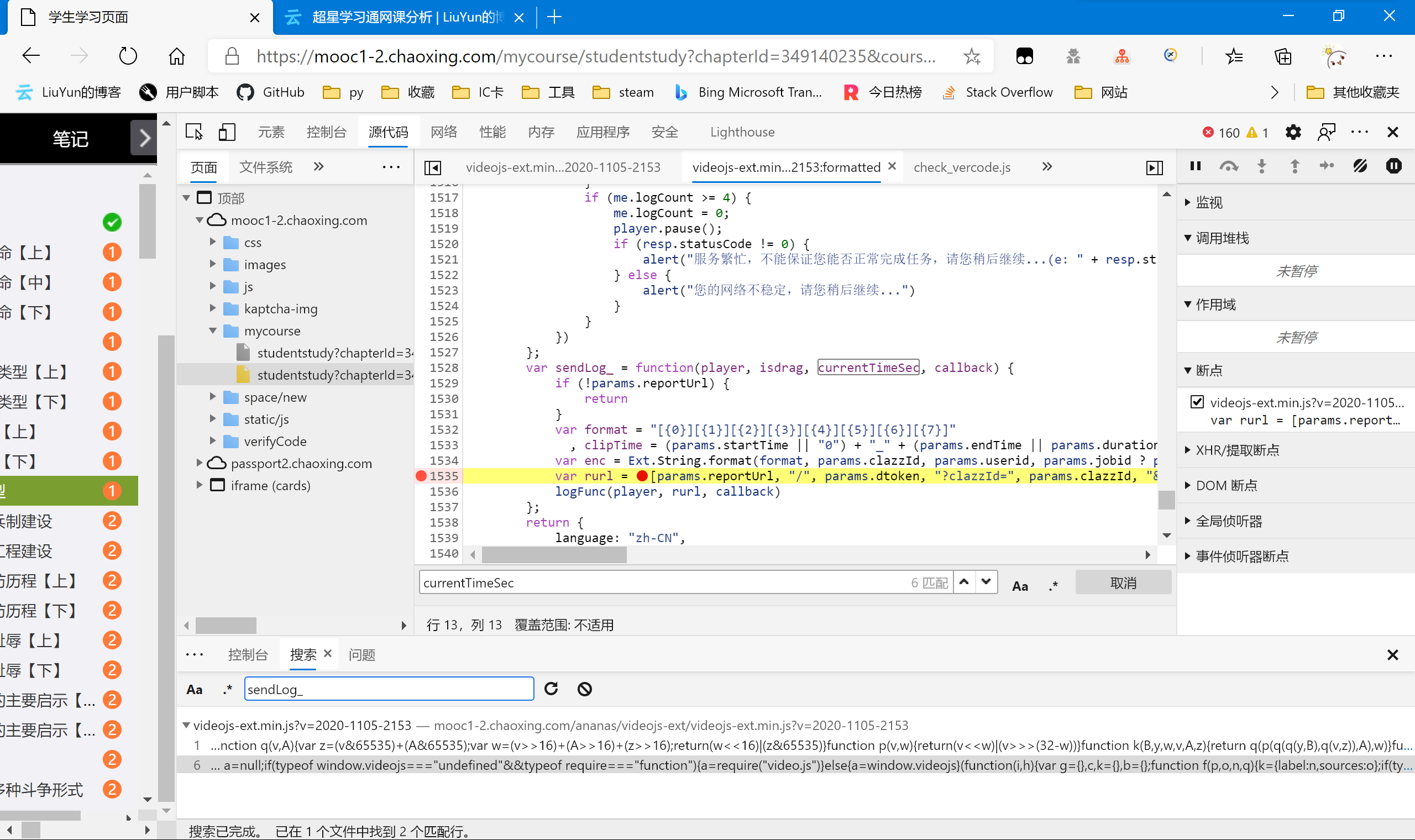
在这里设置断点,然后我们刷新后重新播放视频。将鼠标移到enc处,即可看到enc的值预览。
 这里因为隐私问题做打码处理,可以自己尝试,和我们前面说的基本无二。而currentTimeSec我们也发现了,currentTimeSec * 1000跟 duration * 1000 的值一模一样。
这里因为隐私问题做打码处理,可以自己尝试,和我们前面说的基本无二。而currentTimeSec我们也发现了,currentTimeSec * 1000跟 duration * 1000 的值一模一样。
截止目前,数据包里面的所有参数我们已经都弄明白了,接下来就是写代码就好了。
代码书写
以下是enc的返回函数
| def encode_enc(clazzid:str,duration:int,objectId:str,otherinfo:str,jobid:str,userid:str):
import hashlib
data="[{0}][{1}][{2}][{3}][{4}][{5}][{6}][0_{7}]".format(clazzid,userid,jobid,objectId,duration*1000,"d_yHJ!$pdA~5",duration*1000,duration)
print(data)
return hashlib.md5(data.encode()).hexdigest()
|
然后是数据包的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| if video_item.get("isPassed") == True:
pass
else:
if video_item.get("type") == "video":
objectId=video_item.get("objectId")
otherInfo=video_item.get("otherInfo")
jobid=video_item.get("jobid")
name=video_item.get('property').get('name')
status_url="https://mooc1-1.chaoxing.com/ananas/status/{}?k=&flag=normal&_dc=1600850935908".format(objectId)
status_rsp=requests.get(url=status_url,headers=class_headers)
status_json=json.loads(status_rsp.text)
duration=status_json.get('duration')
dtoken=status_json.get('dtoken')
print(objectId,otherInfo,jobid,uid,name,duration,reportUrl)
multimedia_headers={
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection':'keep-alive',
'Content-Type':'application/json',
'Cookie':cookieStr,
'Host':'mooc1-1.chaoxing.com',
'Referer':'https://mooc1-1.chaoxing.com/ananas/modules/video/index.html?v=2020-0907-1546',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51'
}
import time
elses="/{0}?clazzId={1}&playingTime={2}&duration={2}&clipTime=0_{2}&objectId={3}&otherInfo={4}&jobid={5}&userid={6}&isdrag=4&view=pc&enc={7}&rt=0.9&dtype=Video&_t={8}".format(dtoken,chapter_data.get('clazzid')[0],duration,objectId,otherInfo,jobid,uid,encode_enc(chapter_data.get('clazzid')[0],duration,objectId,otherInfo,jobid,uid),int(time.time()*1000))
reportUrl_item=reportUrl+str(elses)
print(reportUrl_item)
multimedia_rsp=requests.get(url=reportUrl_item,headers=multimedia_headers)
print(multimedia_rsp.text)
|
结语
截止至此,已经是2020/11/20 22:59:16 ,这篇文章还是断断续续写了很久。里面我尽可能展示了我的思路。每一个功能的实现都存在一定的难度性,所以还是很值得记录与分享的。如果你仍有什么疑问,或者我哪里表达较为含糊,您都可以在下方直接评论,或者直接联系我。
最后再次强调,本文仅作为经验分享,请勿将其中内容二次修改用作商业用途。如有侵权也请联系我删除。
最后本文的全部代码已被我整合上传到了GitHub,详细请移步我的仓库 chaoxing_tool ,如果不介意的话可以给我个star支持下。