【issue 已解决】一次gzip导致的编码问题
本文最后更新于:2020年9月20日 早上
前言
为了省去每日都要手动签到的麻烦,我想要做一个某机场的自动签到。综合分析下来,技术难度并不大,只是普通的两个request包,一个实现登录,一个实现签到即可,而且并无啥验证码或者sign验证等。
而当我尝试写完了所有代码,完事具备只欠东风时,却发现返回的结果莫名乱码了。
尝试
编码问题
既然出现了乱码,理所当然第一时间想到的就是response的解码出现了问题。于是我尝试手动设置为UTF-8解码,因为我看了下网页源码里有指明charset为UTF-8
1 | |
结果出乎意料,我的问题并没有得到解决,返回的内容仍然是乱码状态。于是我又尝试了其他编码:gbk,gb2312等。结果都没有返回我想要的正确字符。
GZIP问题
注意到gzip是由于我将乱码的字符放到了搜索引擎,发现也曾有人提出过类似的问题,并且给出了gzip的相关内容,可惜涉及的不深,内容也比较少。于是我在了解到可能是gzip问题时就尝试自己发掘错误。
我观察了我的response-headers,发现其中正好有gzip'accept-encoding':'gzip, deflate, br', ,于是我猜测可能是python在进行解码时并未先对返回内容进行gizp解压,从而导致的乱码错误。
然后我就上网查阅了python相关的gzip调用解压,在response解码前先对其进行gzip解压。结果依然是乱码,到此我便陷入了深深的困惑,这个问题一直卡了我三四天。
解决方案
其实到了上面的gzip,我已经离答案非常解决了,可惜我错想了一步。我认为的是response本身已经gzip压缩了,但python没有解压。而实际情况则是response本身没有压缩,而python读取到headers里的gzip,自动为response进行了解压。结果就导致了上面出现了乱码。
最后的修改也很简单,只需要手动将accept-encoding中相关的gzip删除,以防止python的错误判断即可。
1 | |
再次尝试,问题成功得到了解决。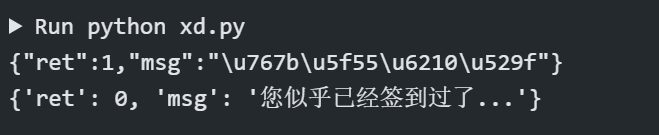
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!